Nowadays cloud is everywhere, cloud is important to many enterprises – and for good reason! With cloud approaches, one gets the benefit of understanding resources as pool, which allows utilizing them according to the currently given needs.
But cloud is complex, especially, if you want to be in control: You need to set up your infrastructure, you need to automate it, you need to maintain it, you need to learn many things. Many organizations start with this approach, try to set up their own cloud stacks and end up being unsuccessful, because complexity is overwhelming and integration of components might take days, weeks, even months.
The result: A lot of money burned, many hours invested – and no outcome. As a consequence, organizations switch to public cloud and hyperscaler environments, ultimately outsourcing their cloud stacks and giving away control over what is actually running and where their most important asset – their data – is stored, how it is handled, and what is happening to it.
Introducing VanillaStack
Cloudical has been in the integration game for years, with its engineers having set up many customer environments, integrated open source and proprietary products and automated the steps necessary for setting up production grade environments.
VanillaStack takes this experience and turns it into a product: A complete end-to-end open source cloud stack, designed to be rolled out fast and always in a working setup. VanillaStack takes away the inherent complexity of modern cloud software by providing a simple and easy to use browser-based frontend. VanillaStack itself is open source, published under the Apache 2.0 license (fig. 1).
But VanillaStack is more than “just” an installer, although that would be a value on its own. Instead, it is a new approach to how a cloud stack is to be set up and organized.
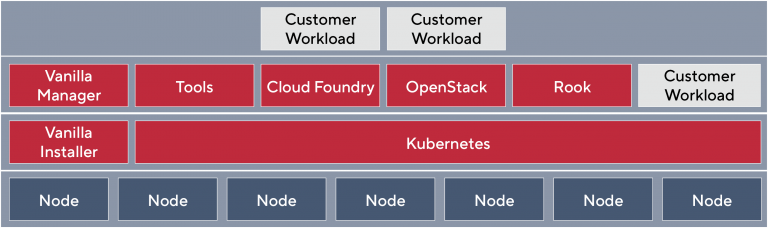
Fig. 1: VanillaStack in Schematic View
Kubernetes as Operating System
VanillaStack understands Kubernetes as its operating system. This allows some fundamental changes in how to perceive a software stack, since it is focusing on the networking aspect, instead of putting single machines with Linux into the focus. Linux is understood to be there, pretty much as one would understand a driver to be present when running an operating system.
Shifting the focus towards Kubernetes allows for becoming independent from the underlying Linux system. Thus, VanillaStack supports different Linux-distributions: Debian 10, CentOS 8, Fedora 32, Ubuntu 20.04 LTS, OpenSUSE Leap 15.2. Additionally, VanillaStack runs on these commercial Linux distributions: SLES 15.2 and RHEL 8. Put it in different words, VanillaStack does not impose any vendor lock on the Linux side of things.
In fact, this avoidance of a vendor lock is a fundamental principle of VanillaStack: The platform is designed to be as open as possible. A vendor lock should not be imposed, if possible, alternatives should be available.
With Kubernetes as its core, VanillaStack is the perfect starting point for cloud-native operations, since it provides a distributed, container-centric solution, which includes all required components and tools for being production ready right from the start (fig. 2).
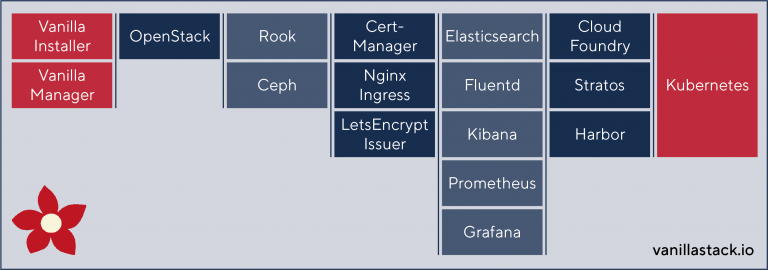
Fig. 2: VanillaStack in Component View
A complete cloud stack
Although VanillaStack is based on Kubernetes, it aims to be way more than just a container operator, since it represents many products being bundled into one.
Let’s touch on some of these projects:
- Kubernetes as container operator
- Docker and CRI-O as container format and runtime
- Rook and Ceph as built-in storage solution
- OpenStack as Infrastructure as a Service layer
- KubeVirt as a simple way of “just running” virtual machines within Kubernetes
- Cloud Foundry as Platform as a Service layer
- Harbor as container registry
- Prometheus and Grafana for gathering and visualizing metrics
- Elasticsearch, Fluentd and Kibana for log aggregation
- Jaeger as tracing framework
- Clair, Aqua and Falco as security frameworks
- Cert-Manager and Let’s Encrypt for certificate handling
- Kubernetes Dashboard for those, who like using it
All of these projects (and many more) are already part of VanillaStack (fig. 3). They are easily to be rolled out, since VanillaInstaller and Infrastructure-as-Code-approaches take away all the pain typically associated with setting them up by hand. Internally, the system uses Ansible Playbooks for rolling out all projects, already prepopulated with useful settings. In the frontend, only selected settings can be altered, resulting in a working, production ready installation.
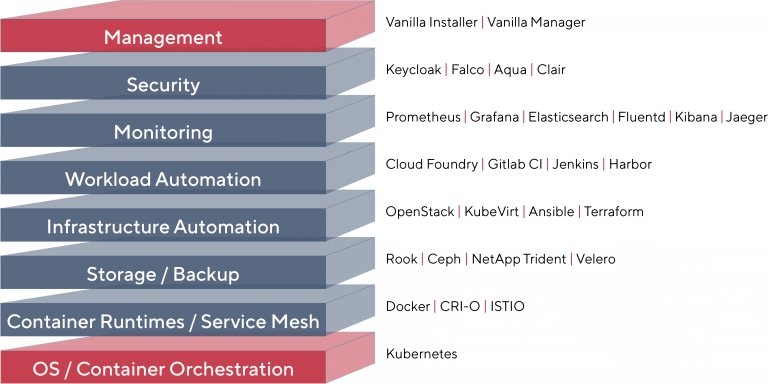
Fig. 3: VanillaStack components
Community Driven
The “Vanilla” in VanillaStack is present with a purpose: It represents the fact that VanillaStack is based on the vanilla versions of the projects being included. This allows to circumvent any of the vendor locks typically imposed with commercial versions of the projects – they expect a specific Linux to be present or require an additional product of the same vendor to be installed, etc. None of these annoyances are given with VanillaStack.
Instead, VanillaStack unleashes the power of the community: The vanilla versions of the projects are typically the best developed and most widely used versions. They have a dedicated and caring community, huge companies support them with the work of their engaged engineers, since these versions build the foundation of their vendor-specific offerings. This makes them a perfect fit with VanillaStack, since these projects are matured and supported. But, unfortunately, installation and maintenance tend to be more complicated and commercial support is typically not available.
Fortunately, VanillaStack addresses both issues: With VanillaInstaller and VanillaManager, setup and operations of the projects being included in the stack is straightforward and simple (just have a look at the screenshots). And with VanillaStack Flat and VanillaStack Modular, two commercial support models are available.
Therefore, VanillaStack combines the best of both open source worlds: the community-approach of the most widely used projects, and the caretaking and supportive approach of commercial offerings.
VanillaInstaller: A working cloud-native stack in less than 30mins
An area where even skilled administrators and operators tend to struggle, is correct and operational grade installation of multiple components. As described above, this is what VanillaStack solves. Let us get through the process of setting up a production ready Kubernetes cluster with Vanilla Installer.
When the installation starts, the first highlight is the selection of the installation kind and the basic workloads to be deployed. Generally, VanillaStack can roll out Kubernetes in HA- and Non-HA-configurations, which is achievable by simply toggling the respective toggle (fig. 04).
Then, the selection of the initial workloads is to be made. Here, three options are available: Rook, OpenStack and Cloud Foundry (fig. 5).
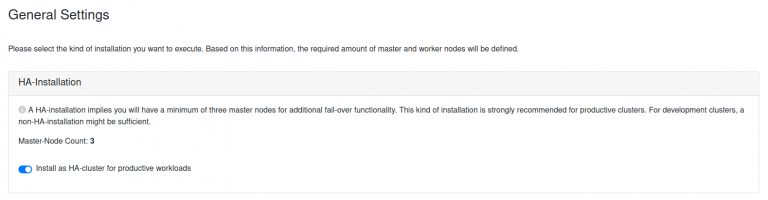
Fig. 4: Selecting the installation kind
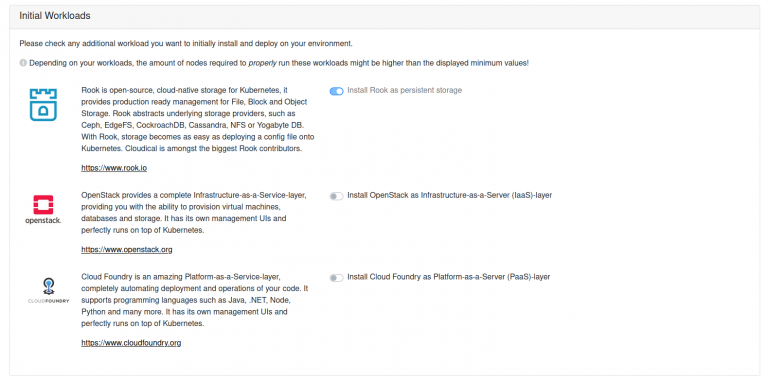
Fig. 5: Selection of initial workloads
Rook is the built-in storage solution. With VanillaStack, Kubernetes cluster always have their own storage built-in, so they can be utilized in production ready scenarios. Rook is based on Ceph, which is an open source object storage solution. Rook and Ceph require a minimum of three worker nodes to be present since stored data is replicated across these workers.
OpenStack is a fully featured Infrastructure as a Services layer. It provides the option to define, store and execute virtual machines, allows for custom network definitions and enables for a complete end-to-end private datacenter environment. It can be installed later as well. Some of the basic functionalities (such as running VMs on top of Kubernetes) can be replicated by KubeVirt, which is an additional functionality rolled out by Vanilla Manager after a successful installation.
Cloud Foundry provides a complete Platform as a Services solution. It allows automated build and automated deployment, as well as automated operations of code. It supports several programming languages, such as Java, .NET, Python or NodeJS, and is an ideal starting point for ISVs since it drastically simplifies any development and deployment process. Cloud Foundry can be installed later as well using VanillaManager. Alternatives, such as GitLab Community Edition or Jenkins will be available using VanillaManager as well.
Following this selection, the number of worker nodes is to be defined. Since Rook requires a minimum of three workers, this is the starting point. As of now, VanillaStack supports up to 99 nodes per cluster (fig. 6).

Fig. 6: Choosing the number of workers
After these base selections have been done, the user is required to copy the installer’s SSH-key onto each of the target machines. This is the only time, where contact with a console is required. Then, the IP-addresses of workers and masters, as well as the usernames to access these machines, have to be made available to the installer (fig. 7).
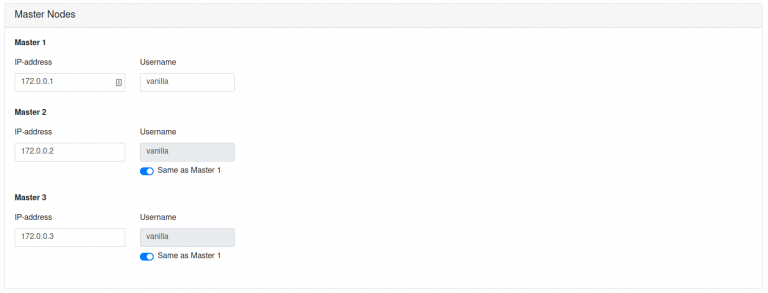
Fig. 7: Assigning IP-addresses and usernames
Before testing the nodes for availability and compliance towards the system requirements, one last task must be fulfilled: Assigning the workloads to the different workers (fig. 8).
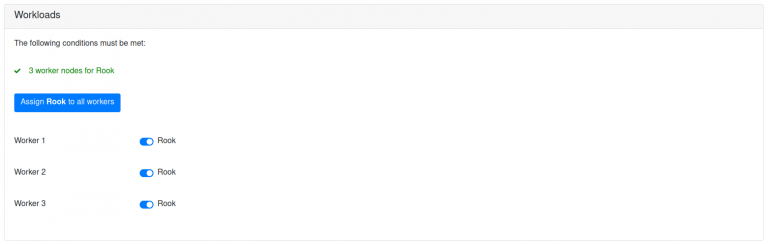
Fig. 8: Assigning Workloads to worker-nodes
Then, once the validation of requirements is done, several additional settings have to be approved or filled out: Cluster-settings come first, followed by Let’s Encrypt and Rook. The cluster-settings allow for definitions of Pod- and Service-CIDRs, and – most importantly – for the definition of the DNS-name the cluster is assigned (fig. 9). This DNS-name, which needs to be a wildcard-domain, is used throughout the system to connect the dashboards of the installed workloads.

Fig. 9: Defining the cluster name
Having set some more settings regarding Rook and other initial workloads (only applicable when selected), the customer can select more workloads to be rolled out initially. Here, the operational tools of choice can be selected and subsequently easily rolled out (fig. 10). All tools selectable here will be integrated and provisioned in a working state, ensuring no additional work other than configuring dashboards and data-origins would be required.

Fig. 10: Selecting additional workloads
Here, the operational tools of choice can be selected and will be rolled out. For a production ready cluster, Prometheus and Grafana to fetch and visualize metrics should be selected. The same is true for Harbor, to store container images and avoid from being dependent of an external container registry. If custom software should be rolled out, the EFK-stack (Elasticsearch, Fluentd and Kibana) should be selected as well. And if performance should be traced, Jaeger would be a perfect complement at this stage as well.
This is about it, more knowledge and interaction are not required when setting up VanillaStack with an operational focus.
Before starting the installation process, the user can select from complimentary commercial software offerings within VanillaStack (fig. 11). This allows a simple installation of supported commercial products, which can – depending on the product – be simply unlocked and transferred onto the VanillaStack cluster.
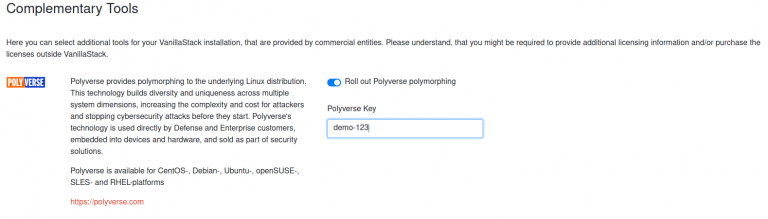
Fig. 11: Selection and installation of complementary tools
Once all of these steps have been successfully mastered and the subscription identification data has been entered, VanillaStack is installed automatically. This can take – depending on the customer’s network speeds, the speed of hard drives or SSDs, and whether the environment is set up bare-metal or on virtual machines – from 25mins up to several hours. Even with additional workloads, such as OpenStack and Cloud Foundry, a typical installation takes less than 45mins (fig. 12).
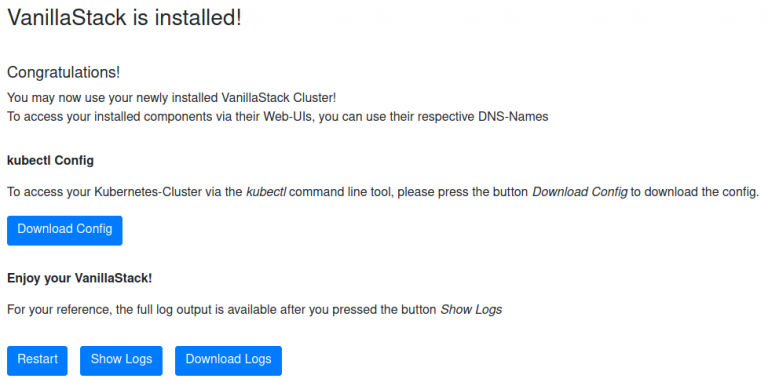
Fig. 12: VanillaStack is installed
And the result? Is a fully working, completely set-up Kubernetes cluster! Different to other stacks, VanillaStack will have installed all the required components for having a production ready Kubernetes cluster with operational tools at the customer’s disposal. And as a bonus: With VanillaStacks commercial support options, help and support is always available – up to 24/7!
Operational Readiness in the shortest time possible!
VanillaStack is created from experience with set up and running containerized and VM based workloads on different environments and ecosystems. It provides answers to those looking for a simple-to-set-up but fully functional and operational container and VM environment. It allows rollouts in the shortest time possible and with most of convenience. It abstracts from all the details, allowing to focus operational teams on what really matters: Productivity and the ability to deliver.
To learn more about VanillaStack, head over to https://vanillastack.io. Request your demo today and see the setup speed and performance yourself!
author:

Karsten Samaschke
CEO of Cloudical
Karsten.samaschke@cloudical.io