The cloud report had the opportunity to talk with Kim-Norman Sahm, CTO of Cloudical, about the way cloud computing is going, open source and avoiding vendor lock-in.

Hello, thank you for taking your time! Please introduce yourself and tell us what you do.
I would be very happy to. I am Kim and CTO of Cloudical. Cloudical is, or rather was, a consulting firm for cloud and cloud-native technologies, both on the training level, in the conception and technical implementation. And I deliberately say “was”, we are currently transforming the company from a pure consulting firm to a product company. We’ve been working on products for the last few months and we’re going to expand our product range so that we can offer managed services and the VanillaStack in addition to consulting and training and enablement business.
Okay… What is the VanillaStack?
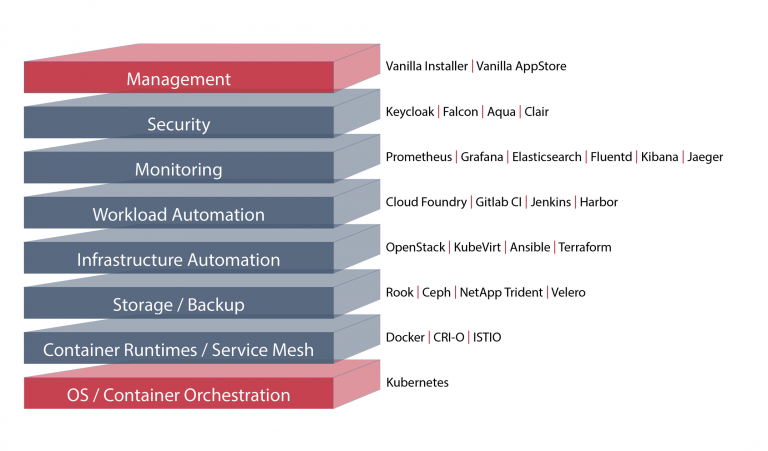
The VanillaStack is a collection of vanilla open source products, not a distributor-branded version of e.g. Kubernetes, OpenStack, Cloud Foundry, which we combine in an easy to deploy framework, which allows the user to easily deploy complex tools like Kubernetes, an IaaS platform like OpenStack and Storage etc. via a web installer. We often see our customers wanting to use these tools, and deploying the tools is not really the problem, it’s more about: I have this zoo of various tools for operation, for logging, for all these second day operations topics, and I have to handle them. And we want to make this as easy as possible for the user: A simple and seamless integration of many components, so, in the end you have one solution and not the zoo of many tools.
That sounds interesting. Especially because these open source tools are driven by different communities, partly also by foundations, which are not really designed to work so seamlessly together. Is that complicated? Or how does it work? How can you bring them together?
Complicated is always relative. The basis for our stack is Kubernetes. We consider Kubernetes as our operating system and say what is underneath doesn’t really interest us, there must be a Linux kernel, there must be a container runtime, and then we are able to roll out our stack on top of it using an Ansible.
Basis is, as I said, Kubernetes, all our workloads should only be rolled out containerized. This makes all the trading, deployment and upgrading easier. The customer also relies on Kubernetes, he can decide which functions he wants to have. Is a pure container platform enough for him? Then he can also deploy his tool set, e.g. in Prometheus, Grafana for monitoring, or the typical EFK stack for logging, these are the things that come with the basic package. And then extensions such as GitLab or other CI/CD tools are possible. In the area of storage, we integrate Rook. Rook = Ceph on Kubernetes, where Cloudical is also a maintainer of.
In this way, the customer can put together his framework according to his needs. The whole is predefined, the whole is integrated and is rolled out automatically.
But we don’t just look at the pure container platform. There are also customers who have a different use case, for whom containers or CaaS alone are not enough. They might need Iaas, maybe a PaaS platform.
For PaaS, we decided on Cloud Foundry, as this is also very strongly seen in the market, especially through Pivotal or SUSE, which has just entered the market with CAP. But we are integrating the vanilla Cloud Foundry solution into the stack.
For IaaS customers we integrate OpenStack, which is my own home base. We build on the OpenStack HELM project, integrate the containerized OpenStack stack into our VanillaStack and thus enable the customer to provide his IaaS platform based on the container platform, for example. Here comes Ceph, here comes OpenStack.
And then we can build on this stack again with other workloads. So, we just ask, why do you have to decide whether it should be a container stack or an IaaS or PaaS? We say: Here is an installer for everything. Just choose what you need and deploy it.
And all this solely based on open source products?
All this on Open Source. We deliberately rely only on open source products for our VanillaStack. We also contribute back to the open source projects. The products are also not touched by us in a big way. If there are adaptations, then these are also made available to the communities, so that they are included in the basic project.
That means, everything you develop in this area will be given back to the communities, so that you can continue developing?
Exactly, this is all open source. We give everything back into the communities, our own developments are provided as open source. We do not want to sell this product, we offer professional and managed services for it. We offer support and managed services based on this stack, if the customer wants to, just like other open source projects do.
Probably you also offer customizations, right?
Exactly.
That sounds a bit like an open source cloud. Why do you think that’s the right step?
We see open source is what people want, and we see the future in open source, in community. And just now, when the European Court of Justice has capped the privacy shield between Europe and the USA. It’s becoming more and more important to know where my data is, who handles my data and how, and what does the software do with my data? For everything I buy proprietary, I have to trust the software manufacturer to tell me that this data really stays in “my” data center and is not synced to the US by some vector at the end.
With open source I can always see the source code, I can integrate my own changes, I have the security, certainty, what the software really does. We see this as a big advantage.
There are various other companies that have taken up the cause of open source, large distributors that make open source and really bring the results back to the communities, there is often a focus on adapting open source software to your own business needs.
So, we want to stay vanilla, we want to use what the communities deliver, we don’t want to change the code a lot to adapt it to our own needs. We actually want to say to the community and the customer: You want vanilla? Here are the tools, here is a framework that allows you to easily deploy these vanilla tools together. But in the end, it’s still the vanilla product. In the end it is Vanilla-Kubernetes, which comes from the Kubernetes community. It is in the end Vanilla-OpenStack, which is developed by the OpenStack community. We have Vanilla-Cloud Foundry with us and everything else that belongs to the zoo.
That means, in the end there are no license fees and you can get help from the communities if necessary?
Exactly.
That sounds as if it hasn’t been there before. This is an exciting step from you.
It is also important to us that this is not just another tool to roll out Kubernetes, it is not just another installer to roll out a Kubernetes distribution. We want to create the installation framework to roll out open source, the combination of Kubernetes, Cloud Foundry, other open source solutions, all based on Kubernetes.
So, I’m curious to see what else is coming. So far there are still plans, but you want to launch it. Do you already have a date when you want to come out with it?
We will release it next week. And it will be big, something big is coming. And because it’s open source, everyone is invited to participate, to contribute, to bring in their own ideas, what can be put on the roadmap, what features are required. It should explicitly not become a cloudical-only solution. It has been developed as an open source project, it has been started as an open source project and we would like other companies and other contributors to join us, so that we can shape it together and make it big together.
Very exciting! Thank you very much for the first insights.
You are very welcome.