The Fantastic 4
Open source is known for many years. It‘s a very well-established way of developing technology collaboratively, which has transformed the way of developing software. And with open source also the way of thinking openness has changed. I.e., the open infrastructure community has come up with the notion of the four opens, to really make sure as a community all are explicit when they do things in an open way. And that has created the four elements open source, open design, open development, and open community.
When we look at the first one – open source, it is important that we look at the complete software stack and make sure that all of its component have an OSI compliant license (1) and are really open and not just some parts are open and other parts are not: for example, are subject to an open core license. We from the SCS-Team reject that. We want to make sure that the licenses give all the rights to the recipients of the software to use the code for whatever they like. For the SCS project we came up with an ‘Open Source Health Check’ that assures components are licensed according to our principles.

The other three “opens” are more about the ability to develop and to participate in the development process. If you want to consume open source software, it is important that you do not only have the rights to receive software and then use it in some way. One of the advantages of open source is that you have the ability to participate in the development process, to shape it, to bring in your ideas, to report issues, to suggest improvements, and to have a reasonable chance that those inquiries are discussed and can be integrated into the open source projects.
And that is what open development, open community and open design are about, the ability to bring in ideas, to see and understand the rational behind decisions as well as to contribute to the codebase. As such, we need an open community where you can participate in. We need a development process that is open, where everybody can participate as well as that design decisions that need to be taken are done in an open and transparent way. Everybody is invited to see what kind of discussions, what considerations led to a decision, and can participate in those discussions and bring in their point of view and even bring in slightly different needs from what other users need.
The fantastic 4 allow everyone to create more value than one captures, which is a quote from Tim O‘Reilly from 20 years ago. This basically is a nice summary on how to view this.
Why a 5th open paradigm?
The fantastic 4 are covering most parts of open source work, but one of the things we’ve learned working with complex infrastructure is: if you build cloud and container platforms having all the pieces, all the components, all of the software stack together as nicely, openly developed open source software components won’t suffice in order to be successful. In the end, operating such systems and platforms is very difficult to do. Even major companies struggle with that.
We looked at the challenges that companies have running such platforms and found out that there is a missing piece with respect to the knowledge regarding the operations part. Well, and then we looked at the open source model. If you run such modern platforms, you typically have DevOps teams: software development and operations integrated into a team typically with some people who are more focused on operations. You link them together very closely. Yet we observed there’s a mismatch: In the development part of it, we have now 20 or 30 years of experience how to organize collaborative working, sharing code with open source, open community and open development principles. On the operations side, we have not yet established such a strong methodology how to best share knowledge, make it accessible and allow people to benefit from that. This observation has led us to say, in the operations part of DevOps, there is further work to be done. We believe there is the need for the same openness as in software development, which we call open operations. We believe it really amends the existing four opens extremely well. The title was actually born out of a discussion that we had during the Open Infrastructure Summit, because we had an accompanying forum session with Red Hat who do the Operate First initiative. (2) While we discussed with them the proposal for the forum session, we somehow came up with the idea of actually referring to open operations as the fifth open paradigm.
Open operations
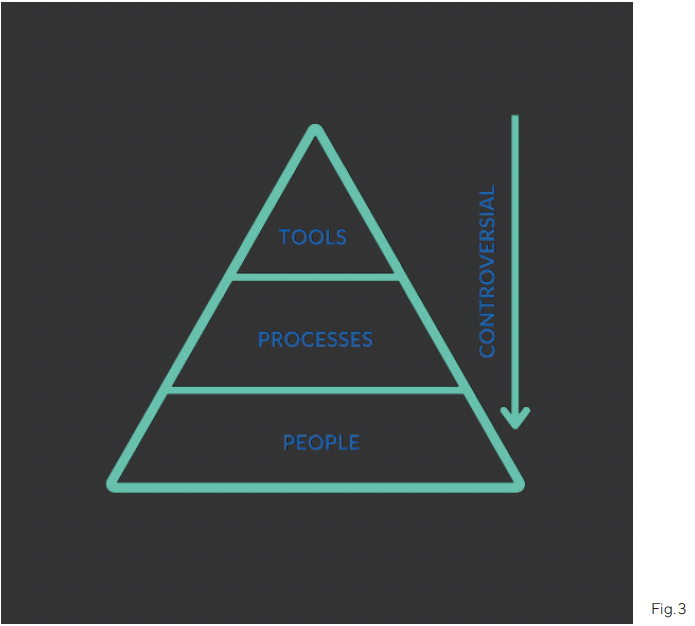
Taking the quote (fig. 2), which basically boils down to what comes after the open source software part. This consists of several things (fig. 3). The tools part is mostly done by open source projects – the question that remains: is open sourcing the tools, dashboards and all that, already enough? The tools part is only one part of the game and actually the most visible and often the most prominent. However, none of the tools would do any good if you don‘t have any good processes in place or good people and culture. Good tools help, but good tools are only very good tools if you have also a good culture in the company and same counts for processes.

To implement good operations the three parts must work together, to illustrate that we use an example in our talk (4), a case study that was done in hospitals and emergency room teams, that thematize the culture aspect, especially focusing on the error culture. One result of the study was that teams are more likely to admit errors, if a healthy error culture has been established and there is no room for blaming. They become more efficient, which means they don‘t make more mistakes, they‘re just more likely to talk about it and have the ability to learn from them.
Building a healthy error culture is a big part of the game. And it is nothing that each and every company should do in private and hidden away from everyone else, but instead talk about it and share the knowledge about how to foster such a culture with everyone else. Since this way everyone else gains from it.
And there is an additional aspect. Figure 3 makes it clear: you have resources that can be easily changed and allocated to something new. And then you have processes that have a longer period of change and are more difficult to adjust. In the end you have the values, the company culture, that‘s the most difficult part to change and to adjust to new challenges. And we have certainly the same challenge with the open operations topic.
With the sovereign cloud stack project we want to build a network of people that work together, a network of different cloud providers, and try to see that we can make them work collaboratively in a way that they can actually build an alternative to some of the largest tech companies in the world. And it would be nice to see this ecosystem of providers and community to be able to succeed together.
In order to do that, all of these companies need to have a lot of knowledge and not all of these companies are very large. So, building that kind of knowledge, getting all the skilled people onboard will not be possible for small companies. By sharing of the existing knowledge, not only in the development of a platform, but also of operating the platform smaller players are able to participate and to be successful. You don‘t need to be huge in order to run cloud. And that‘s what we‘re trying to achieve with the approach of open operations.
Openly speaking about failure? Openly documenting the operational processes?
This is the challenge, but here also lies the solution. A culture of being open and transparent with errors are extremely important things to be successful. And at the same time, it‘s difficult if you come from a culture that does not support error culture as much. This is a difficult cultural change indeed. And we need to be honest at this point. We are in an early stage of the open operation movement. So, we certainly don‘t have all the answers yet. And it‘s not yet mainstream for companies to work that way in operations. But we have started to build our community around that, and we are having success. We‘re having discussions with people, and we have been able to convince people.
And there are some positive examples where companies have made mistakes, things have gone wrong, and because of these there have been platform outages. And they have worked
through this internally and tried to learn from that, and then also shared the knowledge and the learnings they made with the audience, with the public, with their customers. (3) That has been a very positive approach in the end because it allowed customers to reestablish trust and see: okay, things have gone wrong, things have maybe really gone wrong, but we have an organization that has been very careful in analyzing all the aspects, has fully analyzed the issues and has learned from that. And it has been brave and transparent enough to share most of the learnings with the public.
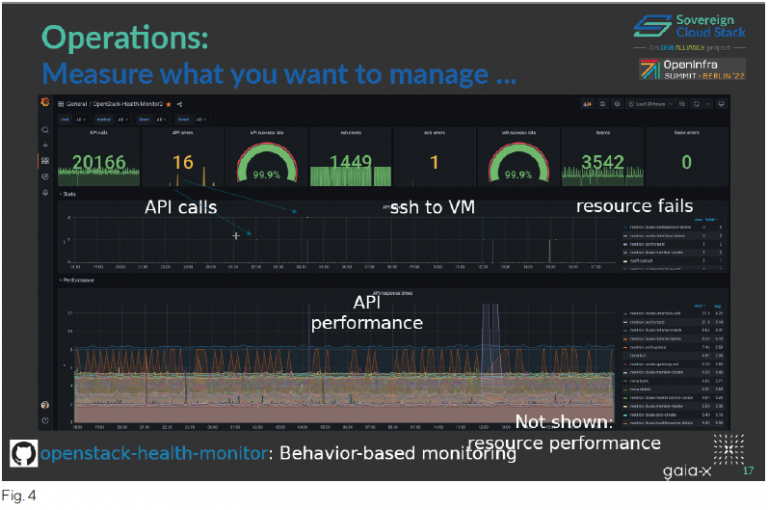
Thinking about open error culture and transparent processes has two dimensions: first the technical, but then the philosophical view. About the technical view: figure 4 is showing the
OpenStack Health Module, which is a tool that was developed a few years ago that we currently use to monitor SCS environments from externally. And we basically used the user credentials to spawn VMs and measure the time and do SSHlogins to these VMs and all that. And we have the idea of providing some sort of a dashboard that is also publicly available because we only do what customers could do. However, we already noticed that raises concerns because it basically shows very fine-grained information on how fast a certain environment is and all that. That‘s the technical part.
The philosophical part is that companies that provide cloud environments are worried, that this kind of transparency could be used against them because customers could observe the quality of services und would start saying: here you were slower than anticipated for example. This could lead to an ideal side effect: a behavioural change in how customers interact with service providers, because the customers know that the service provider is being transparent. And that also causes a culture shift on the customer´s side who doesn‘t try to go into a conflict with the service provider each and every time they see a small dip in graphs.
Next steps to open operations
To implement the 5th open paradigm will be a long way, but we took the first step by talking about it at the Open Infra Summit. (4) The SCS project wants to provide a tool-set for open operations, but also best practices for error culture, transparent documentation and open communication, and a base for community growth in the operations area. Furthermore, we want to spark the discussion among the communities on how to foster this further.
We got some positive feedback at the Summit. Allison Randall came up after the talk and said how much she liked the idea. The idea is to position it as the fifth open and connect it to the already existing four opens which seems logical to get some adoption that everybody says, okay, this is the official fifth open. This will be a longer community discussion. That‘s not something that‘s done by having a few people like it or by maybe having the Open Infra board like it, that‘s not going to happen that way. It will take a longer discussion and we need to build up the community that works in this way and to proof it can be done successfully, that it helps people who are in operations to be successful.
Once we have done that, we would actually have the discussion. So, is it something that is really the official the fifth open in the list of important opens? For us, it is most important to get the idea out there to start these discussions, to meet enthusiastic people who want to contribute, to include operations people at the center of the discussion. Some companies treat the engineers that are responsible for operations not as well as they should be. They don‘t send them enough to conferences or to locations where they could have those discussions. So, we‘re trying to get them out and have that knowledge made available and have those discussions, though. In DevOps we have both – development and operations – we need to think both equally open, transparent, developed: open source, open design, open development, open community and open operations.
Sources:
1. https://opensource.org/licenses
2. https://www.operate-first.cloud/
3. Examples for open error culture and communication: https://azure.microsoft.com/de-de/blog/summary-of-windows-azure-service-disruption-on-feb-29th-2012/ and https://imagefactory.otc.t-systems.com/home/root-cause-analysis-and-improvements-on-otc-network-outage-2017-11-08/
4. https://www.youtube.com/watch?v=oGuUty7ufN8
Authors:

Kurt Garloff
Kurt Garloff has spent his professional life with open source projects. Educated as physicist (in Dortmund and Eindhoven), he has a desire to fundamentally understand things. Applying this to computers made choosing open source a natural consequence. Leading the growth of SUSE Labs, he had the opportunity to forge successful teams from brilliant individuals. Since 2011, his focus is on cloud technology and is an active participant of the Open Infrastructure Community. As VP Engineering at Deutsche Telekom and later as chief architect of the Open Telekom Cloud, he has been involved with building quite some open source cloud infrastructure. Since early 2020, he is working with an increasing number of co-workers on defining and assembling a standardized, open, modular technology stack that enables a large number of operators to jointly provide a large, federated, open cloud. This is the Sovereign Cloud Stack (SCS) project of the Open Source Business Alliance, is part of Gaia-X, has received a significant grant and has released R3 in September 2022.
Contact details: https://scs.community/garloff

Felix Kronlage-Dammers
Felix Kronlage-Dammers has been building (open source) IT Infrastructure since the late 90s. Between then and now Felix was part of various open source development communities (from DarwinPorts, OpenDarwin to OpenBSD and nowadays the Sovereign Cloud Stack). His interests range from monitoring and observability over infrastructure-as-code to building and scaling communities and companies. He has been part of the extended board of the OSBA for the last six years and describes himself as an unix/open source nerd. If not working, he is usually found on a road bike.
Contact details: https://scs.community/kronlage-dammers