Rook allows you to run Ceph and other storage backends in Kubernetes with ease. Consumption of storage, especially block and filesystem storage, can be consumed through Kubernetes native ways. this allows users of a Kubernetes cluster to consu- me storage easily as in “any” other standard Kubernetes cluster out there. allowing users to “switch” between any Kubernetes offering to run their containerized appli- cations. Looking at the storage backends such as minio and CockroachDB, this can also potentially reduce costs for you if you use rook to simply run the CockroachDB yourself instead of through your cloud provider.
Data and Persistence
Aren’t we all loving the comfort of the cloud? Simple back-up and also sharing of pictures as an example. Ignoring privacy concerns for now when using a company for that, instead of e.g., self hosting, which would be a whole other topic. I love being able to take pictures of my cats, the landscape, and my food and sharing the pictures. Sharing a picture with the world or just your family is only a few clicks away. The best of that, even my mother can do it.
Imagine the following situation. Your phone has been stolen and all your pictures in the cloud have been deleted due to a software bug. I, personally, would probably get a heart attack just thinking about that I am a person which likes to look at old pictures from time to time to remember happenings and friends during the time.
You may ask yourself what does this have to do with “Data and Persistence”. There is a simple answer for that. Pictures are data and the persistence is, well in this case, gone because your data has been deleted.
Persistence of Data has a different importance to each of us. A student in America may hope for the persistence to be lost on his student debts and the other may have a job agency which basically relies on keeping the data of their clients not only available and intact but also secure.
Storage: What is the right one?
Block storage
Will give you block devices on which you can format as you need, just like a “normal” disk attached to your sys- tem. Block storage is used for applications, such as MySQL, PostgreSQL, and more, which need the “raw” performance of block devices and the caching coming with that.
Filesystem storage
Is basically a “normal” filesystem which can be consumed directly. This is a good way to share data between multiple applications in a read and write a lot manner. This is commonly used to share AI models or scientific data between multiple running jobs or applications.
Technical note: if you have very very old/legacy applications which are not really 64bit compatible, you might run into (stat syscall used) problems when the filesystem is us- ing 64bit inodes.
Object storage
Object storage is a very cloud native approach to storing data. You don’t store data on a block device and/or filesystem, you use a HTTP API. Most commonly known in the object storage field is Amazon Web Services S3 storage. There are also open source projects implementing (parts) of the S3 API to act as a drop-in replacement for AWS S3. Next to S3, there are also other object store APIs/proto- cols, such as OpenStack Swift, Ceph Rados and more.
In the end it boils down to what are the needs of your applications, but I would definitely keep in mind what the different storage types can offer. If you narrowed down what storage type can be used, look into the storage software market to see which “additional” possibilities each software can give you for your storage needs.
Storage in a Cloud-Native world
In a Cloud-Native world, where everything is dynamic, distributed, and must be resilient, it is more important than ever to keep the feature set of your storage which is used for your customer data. It must be highly available all the time, resilient to failure of a server and/or application, and scale to the needs of your application(s).

This might seem like an easy task if your are in the cloud, but even cloud have limits at a certain point. Though if you have special needs for anything in the cloud you are using, it will definitely help to talk with your cloud provider to re- solve problems. The point of talking to your cloud provider(s) is important before and while you are using their pro- posal. As an example, if you should experience problems with the platform itself or scaling issues of, let’s say, block storage, you can directly give feedback to them about it and possibly work together with them to workout a fix for the issue. Or provide another product which will be able to scale to your current and future needs.
Storage is especially problematic when it comes to scale depending on the solution you are running/using. Assuming your application in itself can scale without is- sues, but the storage runs into performance issues. In most cases you can’t just add ten more storage servers and the problem goes away. “Zooming out” of storage as a topic to persistence, one must accept that there are always certain limits to persisting data. Let it be the amount, speed, or consistency of data, there will always be a limit or at least a trade off.
ROOK IS A FRAMEWORK
TO MAKE IT EASY TO BRING STORAGE
BACKENDS TO RUN INSIDE OF KUBERNETES
A good example for such scaling limits is Facebook. To keep it short, Facebook at one point just “admitted” that there will always be a delay during replication of data/info. They accept that when a user from Germany updates his profile that it can/will take up to 3-5 minutes before users from e.g., Seattle, USA, will be able to see those changes.
To summarize this section: Your storage should be as Cloud-Native as your application. Talk with your cloud pro- vider during testing and usage, keep them in the loop when you run into issues. Also don’t try to push limits which can’t be pushed right now at the current state of technology.
What can Rook offer for your Kubernetes cluster?
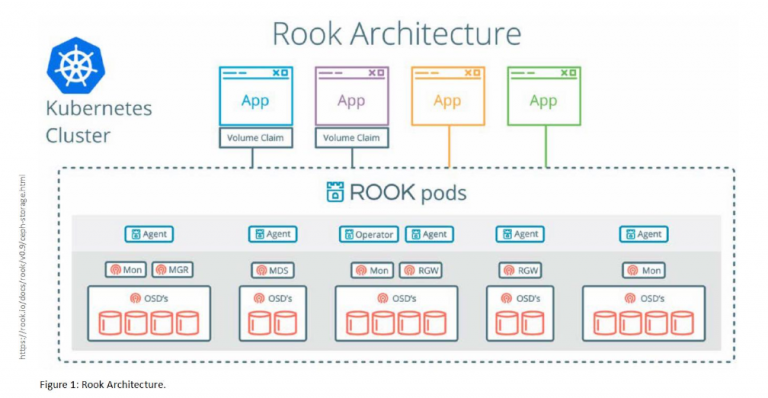
Rook can turn all or selected nodes into “Ceph storage servers”. This allows you to use “wasted” space from the nodes your Kubernetes cluster runs on. Next to “just utilizing ‘wasted’ storage”, you don’t need to buy extra storage servers. You would just keep that in mind during planning the hardware for the Kubernetes cluster (figure 1).

With running storage on the nodes your applications can also run on, the hyperconverged aspect is also kind of covered. You might not get more performance because of your application running on the same node as your storage with Ceph, but Ceph and Rook are aware of this and will possibly look into ways of improving this. Please note that Ceph’s priority will always be consistency even if speed needs to be sacrificed for that.
Ceph is not the only storage backend which can be run using Rook but more on that later.
Rook Kubernetes integration
In Kubernetes you can consume storage for your applications, through these Kubernetes objects: PersistentVolumeClaim, PersistentVolume and StorageClass. Each of these objects has their own role. PersistentVolumeClaims are what users create to claim/request storage for their applications. A PersistentVolumeClaim is basically the user facing side of storage in Kubernetes as it is standing for a PersistentVolume behind that. To enable users to consume storage easily through PersistentVolumeClaims, a Kubernetes administrator should create StorageClasses. An administrator can create multiple StorageClasses and also define one as a default. A StorageClass holds parameters which can be “used” during the provisioning process by the specific storage provider/driver.
You see, Rook enables you to consume storage the Kubernetes native way. The way most operators work in point of their native Kubernetes integration is to watch “simply” for events happening to a certain selection of objects. “Events” are, e.g., that an object has been created, deleted, updated. This allows the operator to react to certain “situations” and act accordingly, e.g., when a watched object is deleted, the operator could run it’s own cleanup routines or with Rook as an example, the user creates a Ceph Cluster object and the operator begins to create all the components for the Ceph Cluster in Kubernetes.
To be able to have custom objects in Kubernetes, Rook uses CustomResourceDefinitions. CustomResourceDefinitions are a Kubernetes feature which allows users to specify their own objects in their Kubernetes clusters. These custom objects allow the user to ab- stract certain applications/tasks, e.g., with Rook the user is allowed to create one Ceph Cluster object and have the Rook Ceph operator create all the other objects (Config- Maps, Secrets, Deployments and so on) in Kubernetes.
Onto the topic of how Kubernetes mounts the storage for your applications to be consumed: If you have already heard a bit about storage for containers, you may have come across CSI (Container Storage Interface). CSI is a standardized API to request storage. Instead of having to maintain drivers per storage backend in the Kubernetes project, the driver maintenance is moved to each storage backend itself, which allows faster fixes of issues with the driver. The normal process when there is an issue in an in- tree Kubernetes volume plugin is to go through the whole Kubernetes release process to get the fix out. The storage backend projects create a driver which implements the CSI driver interface/specifications, through which Kubernetes and other platforms can the request storage.
For mounting Ceph volumes in Kubernetes, currently Rook uses the flexvolume driver which may require a small configuration change in existing Kubernetes clusters. Us- ing CSI with Rook Ceph clusters will hopefully soon be possible when CSI support has been implemented in the Rook 0.9 release. Depending on how you see it flexvolume is just the mount (and unmount) part of what CSI is.
Running Ceph with Rook in Kubernetes
Objects in Kubernetes describe a state, e.g., a Pod object contains the state (info) on how a Pod must be created (container image, command to be run, ports to be open, and so on). The same applies to a Rook Ceph cluster object. A Rook Ceph cluster object describes the user desired state of a Ceph Cluster in their Kubernetes cluster. Below is an example of a basic Rook Ceph Cluster object:
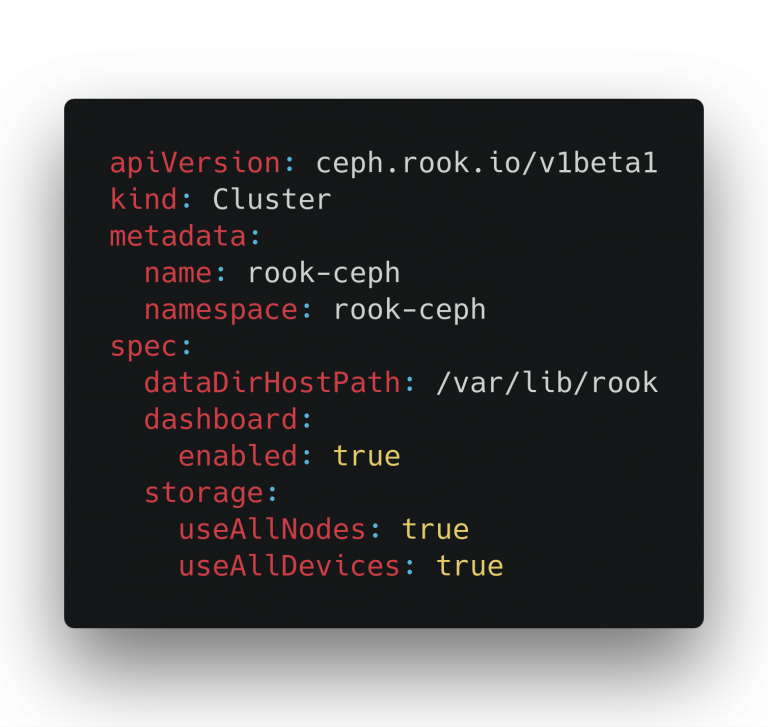
Not going into too much details about the example Rook Ceph Cluster object here, it will instruct the Rook Ceph operator to use all nodes in your cluster as long as they are applicable (don’t have taints and/or other “restrictions” on them). For each applicable node it will try to use all emp- ty devices and store configs and some state data in the dataDirHostPath: /var/lib/rook.
If you would search through the Kubernetes API reference you wouldn’t find this API (ceph.rok.io/v1be- ta1) nor the object kind Cluster. As written in the pre- vious section, user defined APIs and objects (kinds) are introduced by a CustomResourceDefinition to the Kubernetes API. All CustomResourceDefinition of Rook are created during the installation of Rook in your Kubernetes cluster.
Creating the above object on your Kubernetes cluster, with the Rook Ceph operator running, would cause the Rook Ceph operator to react to the event that an object of type / kind Clusterin the API ceph.rook.io/v1be- ta1 has been created.
Before shortly going into what the Rook Ceph operator does now, I give a quick overview about how a “standard” Ceph cluster looks like. A Ceph cluster always has one or more Ceph Monitors which are the brain of the cluster, and a Ceph Manager which takes care of gathering metrics and doing other maintenance tasks. There are more compo- nents in a Ceph cluster, to focus on the third which is next to the Monitors and Manager the most important thing which will store your data. Ceph Object Storage Daemon (OSD) is the component which “talks” to a disk or directory to store and serve your data.
The Rook Ceph operator will start and manage the Ceph monitors, Ceph Manager and Ceph OSDs for you. To store data in so called Pools in your Ceph cluster, the user can simply create a Pool object. Again the Rook Ceph operator will take of it and in this create a Ceph pool. The pool can then directly be consumed using a StorageClass and PersistentVolumeClaims to dynamically get PersistentVolumes provisioned for your applications.
This is how simple it is to run a Ceph cluster inside Kubernetes and consume the storage of the Ceph cluster.
Rook is more than just Ceph
Rook is a framework to make it easy to bring storage back- endstoruninsideof Kubernetes. Thefocusfor Rookistonot only bringing Ceph which is for block, filesystem and object storage, but also for persistence on a more application specific level by running CockroachDB and Minio through a Rook operator. Due to have the abstraction of complex tasks/applications through CustomResourceDefinitions in Kubernetes, it is as simple as deploying a Ceph Cluster as shown with the above code snippet.
To give a quick overview of the currently implemented storage backends besides Ceph, here is a list of the other storage backends:
- Minio – Minio is an open source object storage which implements the S3 API.
- CockroachDB – CockroachDB provides ultraresilient SQL for global business. Rook allows you to run it through one object to ease the deployment of CockroachDB.
- -NFS – NFS exports are provided through the NFS Ganesha server on top of arbitrary
PersistentVolumeClaims.
For more information on the state and availability of each storage backend, please look at “Project Status” section in the README file in the Rook GitHub project. Please note that not all storage backends here are available in Rook version 0.8, which is at the point of writing this article the latest version, some are currently only in the latest development version but a 0.9 release is targeted to happen soon.
Rook project roadmap
To give you an outlook of what can be to come up, a sum- mary of the current Rook project roadmap:
- Further stabilization for the
CustomResourceDefinitionsspecifications and managing/orchestration logic: - Ceph
- CockroachDB
- Minio
- NFS
- Dynamic provisioning of filesystem storage for Ceph.
- Decoupling the Ceph version from Rook to allow the users to run “any” Ceph version.
- Simpler and better disk management to allow adding, removing and replacing disks in Rook Ceph cluster.
- Adding Cassandra as a new storage provider
- Object Storage user
CustomResourceDefinition,to allow managing users by creating, deleting and modify- ing objects in Kubernetes. - There is more to come for a more detailed roadmap, please look at the roadmap file in the Rook GitHub project.
How to get involved?
If you are interested in Rook, don’t hesitate to connect with the Rook community and project using the below ways.
- Twitter – @rook_io
- Slack – https://rook-io.slack.com/
- For conferences and meetups: Checkout the #conferences Channel
- Contribute to Rook:
- https://github.com/rook/rook
- https://rook.io/
- Forums – https://groups.google.com/forum/#!forum/ rook-dev
- Community Meetings
Author:

Alexander Trost
DevOps Engineer at Cloudical Deutschland GmbH