What’s the story with Trident?

Container technology received a lot of attention recently and has become essential for cloud native deployments. However, all that glitters is not gold and the technology has a few drawbacks. The Cloud Native Computing Foundation identified within their most recent surveys the limitations within the areas of storage and security. The following article describes how to deal with persistent storage requirements in hybrid cloud environments. Furthermore, it describes possible solutions by taking advantage of dynamic storage orchestrators such as Trident and its related architecture. Lastly, a brief description regarding its deployment and advantages is given.
As the Greek philosopher Heraclitus stated: “change is the only constant” one thing is for sure: Societies are constantly reinventing themselves to improvise and make sure daily routines continue. This paradigm applies to lots of industries. As someone who lives in Hamburg, one of the major European port cities, change is ubiquitous and present on a daily basis. For example, roughly 50 years ago virtually all goods were shipped around the world in a loose manner, crammed into old fashioned cargo ships. Due to standardisation, today nearly 90% of non-bulk cargo is transported by container vessels globally. Figure 1 undermines the continued growth of global container trade since 1996.
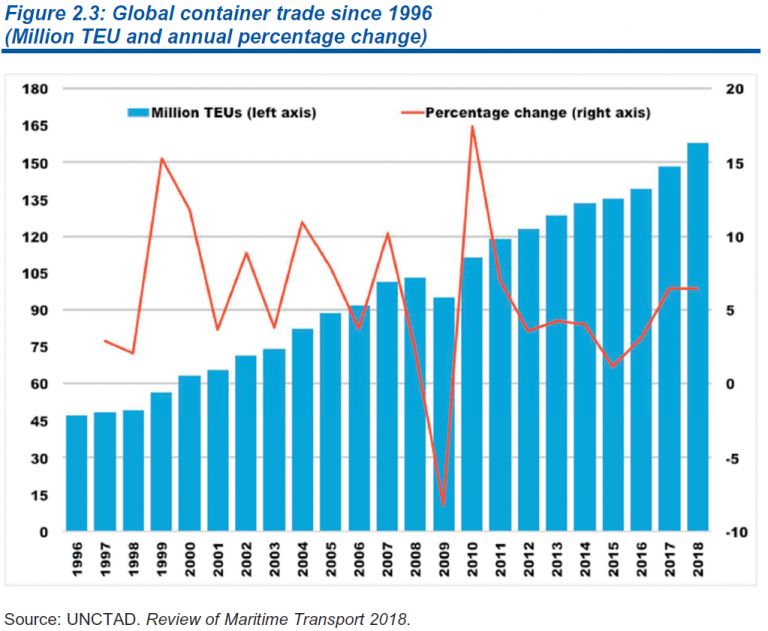
Fig. 1: Global Container Trade since 1996
The impact of containerization was enormous for port infrastructures since a lot of existing concepts such as storage sheds, finger piers & berthing space became suddenly obsolete. To remain competitive, port cities were forced to completely rethink their operations by developing new terminals to accommodate container vessels coming in.
Another great example confirming the paradigm of constant change and their related infrastructures can be observed within the tech-industry. Regarding virtualization, we have come from bare metal deployments through virtualization techniques to the concept of containerization; this represents different levels of logical abstractions for a specific type of resource, such as hardware components or application layers. Obviously, each concept has its pros and cons and its right to exist given specific use-cases. A striking characteristic of those concepts is the difference to the underlying amount and type of infrastructure needed to utilize resources.
The container technology sparked a lot of interest due to its value acceleration, i.e., optimal and accelerated development pipelines that enable software development teams to deploy consistent applications (in a packaged form), all the time, no matter of its location. Another treat is related to cost savings. Containers aid the infrastructure utilisation since the resource footprint is relatively small. Also, since it is open source based, there is hardly any vendor lock-in.
This perception has also been confirmed within the Cloud Native Computing Foundation (CNCF) Survey 2020. Whereas the use of containers in production has increased to 92%, up from 84% in 2019, and up 300% from the first survey conducted in 2016.
However, all that glitters is not gold and the technology does have a few weak points leading to challenges for its adoption. According to the CNCF Survey 2020, one of the top two technical challenges are within the area of storage and security (as indicated within figure 2).
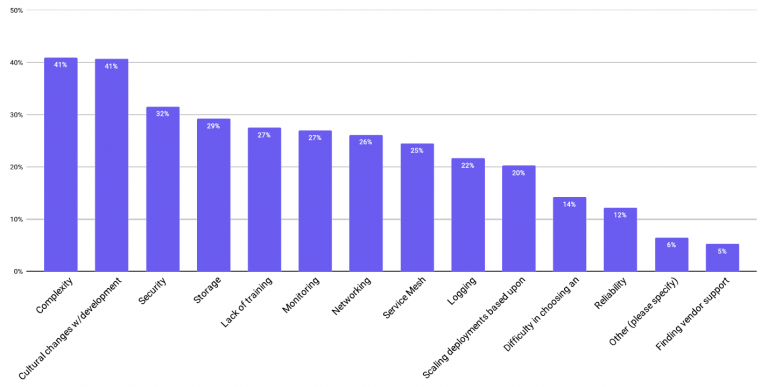
Fig. 2: Challenges in using/deploying containers – CNCF Survey 2020
When it comes to storage requirements it’s important to understand that containers were initially developed for stateless applications using temporary (ephemeral) storage provided within a Kubernetes Cluster to maintain portability and flexibility. Once a Container is deleted or accidentally shut down the storage will not be available anymore. This may be beneficial for stateless applications streamlining the storage footprint once the task has been completed. Though, stateless application may not always be needed, in particular for enterprise applications. According to the CNCF Survey 2020, only 22% of the participants claimed to use stateless applications. 55% claimed however, to run stateful applications in production requiring persistent storage (fig. 3).
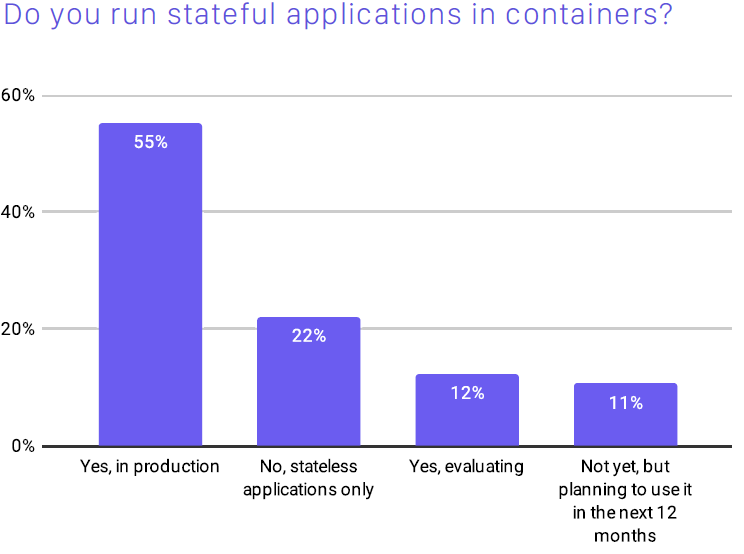
Fig. 3: Using stateful application – CNCF Survey 2020
Hence, persistent storage for container environments is a major requirement. For stateful applications, workloads must stay attached to its dedicated storage environment in a persistent manner demanding mostly storage outside the K8s Cluster (such as NAS). Also, there must be a way to create volumes once a pod is created providing data even if the app crashes. This gets even more complex for hybrid scenarios, requiring a platform independent of its location. Whether it be on- or off-prem scaling independently. If you are moving from one hyperscaler to another, you would expect that your data moves along as well as all its characteristics i.e., retention, backup and performance policies.
For being able to provision persistent volumes, a manual persistent volume claim (PVC) can be executed by admins to grab the required amount of storage which would need to be pre-provisioned. This might be a solution for small and medium sized clusters where no automation is needed. However, there might always be a delay in providing the PVC since it requires a manual response. To automate this process, dynamic storage provisioners would aid the problem. Obviously, there are lots of dynamic storage provisioners available, both open source projects and commercial offerings. A summarized list is displayed in table 1.
| Product | Vendor |
| Container Storage Platform | Red Hat |
| Kubera | MayaData |
| Portworx | PureStorage |
| Robin | Robin Systems |
| StorageOS | StorageOS |
| Trident | NetApp |
| Project | CNCF Status |
| Ceph | Not Submitted |
| LongHorn | Sandbox |
| OpenEBS | Sandbox |
| Rook | Incubating |
Table 1: list of Dynamic Storage Provisioners
Within the following chapter, we are going to describe thoroughly the storage provisioner “Trident” offered by NetApp.
What’s the story of Trident?
Trident is a dynamic storage orchestrator providing the ability to manage storage resources across all major NetApp storage platforms. Due to the integration with the container storage interface (CSI), it natively integrates with K8s to dynamically provision persistent storage volumes on demand upon request. Based on the integrated REST interface, it can be used by any application to manage storage across the configured infrastructure. For example, those could be popular application container platforms and orchestrators such as RedHat OpenShift, Rancher or Google Anthos. Also, Trident is an open source solution that is fully supported by NetApp. In other words, while it’s free, customers can get technical support under existing contracts.
Trident offers the ability to use multiple storage backends simultaneously. This implies, that each backend having a different configuration can be utilised based on its characteristics providing specific performance requirements.
Of course, advanced data management features like the following are also available:
- volume imports: supporting disaster recovery or lift and shift scenarios
- volume resize for, i.e., expanding volume sizes according to the user needs
- volume snapshot/cloning: a point in time copy of the data & state of the volume for, i.e. backup & retention requirements
- Trident Operator: a controller to manage lifecycle of Trident resources in K8s with the integration of Helm Charts to simplify large scale deployments
- Prometheus Metrics: to ensure close monitoring of a variety of metrics
A general overview of Tridents architecture is represented within figure 4.

Fig. 4: General architecture of Trident
Good enough, but how does it really work?
Throughout the following chapter, we are going to illustrate how the provisioning process looks like. This process has two primary parts: First, associated storage classes with a set of suitable storage pools would need to be created. The second part considers the volume creation by choosing a storage pool meeting the associated storage class requirements.
To assign the backend storage to storage pools related to a storage class, several attributes can be defined. Those can be attributes such as media (i.e., hdd, hybrid, ssd), provisioning type (thin, thick), backend type, snapshot, clones etc. Once a user creates a storage class, Trident compares the required attributes and pools available within the backend. If a storage pool’s attribute matches with the requested class attributes, Trident adds all storage pools to the set of suitable storage pools for that specific class.
Once the storage pools and classes are defined, volumes can be provisioned for specific applications. This can be done the following way:
- A user creates a PersistentVolumeClaim requesting a new PersistentVolume of a particular size from a Kubernetes StorageClass that was previously described.
- The Kubernetes StorageClass identifies Trident as its provisioner and includes parameters that tell Trident how to provision a volume for the requested class.
- Trident looks at its own Trident StorageClass with the same name that identifies the matching Backends and StoragePools that it can use to provision volumes for the class.
- Trident provisions storage on a matching backend and creates two objects: a PersistentVolume in Kubernetes that tells Kubernetes how to find, mount and treat the volume, and a Volume in Trident that retains the relationship between the PersistentVolume and the actual storage.
- Kubernetes binds the PersistentVolumeClaim to the new PersistentVolume. Pods that include the PersistentVolumeClaim will mount that PersistentVolume on any host that it runs on.
To illustrate the configuration and deployment process, figure 5 visualizes the process described above.
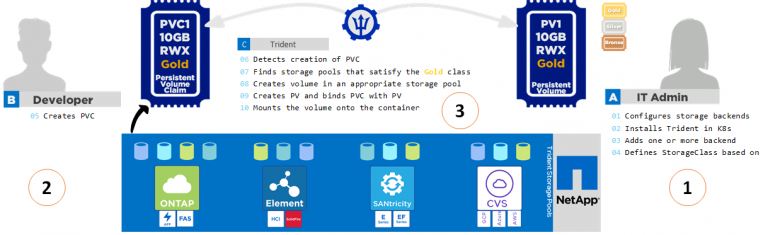
Fig. 5: Trident Storage Provisioning
To sum things up, Trident is a powerful storage provisioner to take full advantage of new software development and delivery paradigms within the container eco-system by supporting the following features (table 2):

Table 2: Trident features
Furthermore, it overcomes the described challenges concerning persistent storage to deploy stateful applications in a production and enterprise ready environment.
In case you would like to know more, I would encourage you to consult the following sources:
ThePub: netapp.io
Slack: netapp.io/slack
GitHub: github.com/NetApp/trident
Sources:
https://unctad.org/system/files/official-document/dtl2018d1_en.pdf
https://www.cncf.io/wp-content/uploads/2020/11/CNCF_Survey_Report_2020.pdf
https://www.cncf.io/wp-content/uploads/2020/08/CNCF_Survey_Report.pdf
https://netapp-trident.readthedocs.io/en/stable-v18.07/kubernetes/concepts/provisioning.html
Author:

Erik Lau, Solutions Engineer
Erik has a love for technology and the ability to tie technical concepts back to underlying business needs. He works at NetApp as a Solutions Engineer helping customers discovering technical solutions tackling demanding business challenges within the field of Cloud Computing and Data Management.
Twitter: @herrlauer
![]()