The OpenStack Foundation’s virtual OpenDev event this summer created a space for engaging conversations on a variety of topics within the open infrastructure community. Packaged into three separate events, each three days in duration, participants discussed open infrastructure software, hardware automation and containers in production. They shared challenges and heard stories on use cases from notable users. In the first session, Blizzard Entertainment, Verizon, and OpenInfra Labs discussed combatting the challenges behind scaling, testing and integration during their presentations to the open source community.
Tales of scaling complexity, performance testing and integration through the eyes of three key users.
The OpenStack Foundation recently hosted OpenDev 2020, a three-part virtual event to bring together and engage with the open source community. Kicking off the event was an opportunity to share what the community has been working on in regards to large-scale use of open infrastructure software, and three interesting user stories were shared on the first day of the event.
For Blizzard Entertainment, it’s “game over” on scaling complexity
Blizzard Entertainment is a California-based software company focused on creating and developing game entertainment for customers in the Americas, Europe, Asia and Australia (fig. 1). In late June, two of the company’s engineering leaders, Colin Cashin and Erik Andersson, talked to the open source community about their cloud strategy and scaling challenges at the OpenDev virtual event focused on large-scale usage of open infrastructure.
Blizzard employs a multi-cloud strategy. The company uses public clouds from Amazon, Google and Alibaba, and since 2016 also owns and operates an extensive global private cloud platform built on OpenStack. Blizzard currently has 12,000 compute nodes on OpenStack distributed globally and even managed to upgrade five releases in one jump last year to start using Rocky. The team at Blizzard is also dedicated to contributing upstream.
All in all, Blizzard values simplicity over complexity and has made consistent efforts to combat complexity by addressing four major scaling challenges.

Fig. 1: Blizzard Entertainment is focused on creating and developing game entertainment
Scaling Challenge #1
The first scaling challenge that Blizzard faced was Nova scheduling with NUMA pinning. NUMA pinning ensures that guest virtual machines are not scheduled across NUMA zones on dual socket compute nodes, thereby avoiding the penalty of traversing oversubscribed bus interconnects on the CPU. For high-performant game server workloads this is the difference between a great and not great player experience. In 2016, they made the decision to implement NUMA pinning during scheduling to prevent these issues, ahead of the launch of Overwatch, Blizzard’s first team-based First Person Shooter (FPS). At scale, this decision caused a lot of pains. NUMA scheduling is expensive and requires a recall to Nova DB, impacting the turnaround time of this process. During particularly large deployments, they regularly ran into race conditions where scheduling failed and ultimately addressed this issue with configuration tuning to increase the target pool for the scheduler from 1 to 20 compute nodes. Another side effect of NUMA pinning was broken live migrations, a hindrance that is now fixed in Train’s Nova release.
The takeaway: For large environments, NUMA pinning should be implemented in a tested and controlled manner. Also, live migration with NUMA profiling is fixed in new releases.
Scaling Challenge #2
Next, Cashin and Andersson discussed scaling RabbitMQ. RabbitMQ is a tool that acts as a messaging broker between OpenStack components but in Blizzard’s case has proven to be easily overwhelmed. Recovering services when something went wrong (e.g. large-scale network events in a data center) appeared to be their biggest challenge at scale, and this wasn’t something that could be overlooked. To tackle this, Blizzard tuned RabbitMQ configurations to introduce extended connection timeouts with a variance to allow for slower but more graceful recovery. Additional tuning was applied to Rabbit queues to make sure that only critical queues were replicated across clusters and that queues could not grow exponentially during these events.
The takeaway: RabbitMQ needs tuning unique to your environment.
Scaling Challenge #3
Neutron scaling proved to be the third biggest hurdle for Blizzard. Blizzard experienced several protracted operational incidents due to having certain OpenStack services co-located on the same controller hosts. The Blizzard team fixed this in 2019 when they decided to scale horizontally by migrating Neutron RPC workers to virtual machines. Moving to VMs also solved the shared fate of the API and worker pools. Additionally, there was the issue of overwhelming the control plane when metadata services proxied huge amounts of data at scale. After much research and conversation with the community, Andersson was able to extend the interval to 4-5 minutes and greatly reduce load on the control plane by up to 75% during normal operations.
The takeaway: Neutron configuration and deployment should be carefully considered as the scale of your cloud grows.
Scaling Challenge #4
Lastly, the issue of compute fleet maintenance had been a concern for Blizzard for quite some time. As their private cloud went into production at scale, there was an internal drive to migrate more workloads into cloud from bare metal. In many cases, this meant that migrations took place before applications were truly cloud aware. Over time, this severely impacted Blizzard’s ability to maintain the fleet. Upgrades involved lots of toil and did not scale. Over the past 15 months, Blizzard’s software team has built a new product, Cloud Automated Maintenance, that enables automated draining and upgrading of the fleet. The product uses Ironic underneath to orchestrate bare metal and a public cloud style notification system, all automated by lifecycle signaling.
The takeaway: Onboard tenants to OpenStack with strict expectations set about migration capabilities, particularly for less ephemeral workloads. Also, have the processes and/or system in place to manage fleet maintenance before entering productio
Going forward, Blizzard will continue to pinpoint and tackle challenges to eliminate complexity at scale as much as they can.[1]
Verizon’s Optimum Performance Relies on Owning the Testing Process
Verizon’s cloud platform, built on an OpenStack infrastructure distributed across 32 global nodes, is used by the networking team to provide network services to commercial customers. Because these applications are commercial products such as firewalls, SD-WAN and routing functions provided by third-party companies, not owned by Verizon, the applications sometimes had odd interactions with the underlying infrastructure and each other.
Issue: Uneven vendor application performance
The product engineering team realized that the applications owned by Verizon’s partners were each configured differently and, depending on how they were each configured, had a significant effect on how they behaved in the environment.
SDN vendor performance variance became a pressing issue that significantly affected throughput in the field. For example, it was discovered that in many cases, when encryption was turned on, throughput was reduced by half. With traffic moving through multiple systems, it became difficult to determine the cause (or, in some cases, causes) of problems and determine the fixes needed. The dramatic variation in vendor capabilities to fully take advantage of virtualized applications and infrastructures to optimize those applications to OpenStack became a major challenge.
Solution: Create platform and processes to address issues
Verizon tackled this issue of inconsistency by building a production engineering lab with full testing capabilities. This lab environment, used for product development, production support, and troubleshooting customer configurations, gives a clear and efficient feedback loop that is useful for informing product managers, sales teams and customers with real world results. For instance, when a customer decides to run voice traffic through a firewall (not a common configuration), with the lab Verizon can access and analyze all the different nuances of that configuration. The lab is also used to work closely with vendors to optimize their virtualized applications. It supports the capacity to test both data center environments and edge devices.
As a consequence of developing the production engineering lab, Verizon now has the ability to insist on thorough and consistent testing of each vendor’s application. Verizon is able to take their customer production traffic and run it through the lab, making it possible to reproduce customers’ issues in the lab environment. Through verifying each application, testing them for performance based on factors like encryption, and making full performance testing on all integrated service chains automated and mandatory, Verizon is able to provide a much higher level of value to their customers to prevent potentially unpleasant surprises.
User Story: Financial Services firm with high security and performance requirements
Customers look to Verizon with high expectations, and Verizon makes sure to work with each of their vendors to provide the testing and support that they need most to meet their SLAs (fig. 2).
One of Verizon’s customers began to experience problems with low bandwidth and application micro freezing. This was a big problem for their security application. After some testing, it was soon obvious that this behavior was common to all security applications running on the virtualized environment. Immediately, the team at Verizon began to make changes to how the VMs were stood up in the environment, without needing to change any aspects of the underlying hosted infrastructure itself.
Because the results of this case study affected nearly every single one of Verizon’s vendor applications, particularly where the customers had latency sensitive deployments and transports larger than 100 Mbps, the company has now developed new standards to support customer configurations. All VMs for future applications are now automatically configured to be pinned to resources to avoid resource contention, vendors are mandated to support SRIOV networking deployment, and customers are cautioned about throughput behavior if they choose to turn on traffic encryption.
Customers want reliable performance, but they not uncommonly put unexpected demands on their services. By building a full lab and testing center, Verizon was able to test customer configurations and troubleshoot issues down to the individual feature level. As a result, Verizon as a large operator now has even more capacity to facilitate cooperation with all of its vendors—ensuring the integrated service chains perform as expected, solving issues uncovered during development or production, and quickly addressing any customer related issues.

Fig. 2: Verizon makes sure to work with each of their vendors to provide the testing and support
OpenInfra Labs on Solving the Open Source Integration Problem
OpenInfra Labs, the newest OpenStack Foundation pilot project, is a collaboration between the OpenStack Foundation, higher education research institutions, and industry (fig. 3). The project was launched in 2019 with the goal of creating a community for infrastructure providers and operators to integrate and optimize different layers of infrastructure; test open source code in production; publish complete, reproducible stacks for existing and emerging workloads; and advance open source infrastructure.
OpenInfra Labs was born out of an opportunity to further several existing interrelated initiatives, currently known as the Open Cloud Initiative (OCI). At the center of the OCI is the Mass Open Cloud (MOC), a public-private partnership between higher education (Boston University, Northeastern University, MIT, Harvard University and the University of Massachusetts) and industry (current core industry partners include Red Hat, Intel and Two Sigma) seeded by the Commonwealth of Massachusetts. The MOC was launched in 2014 with the goals of creating an inexpensive and efficient at-scale production cloud, creating and deploying the OCX model, and creating a testbed for research. The project has demonstrated success towards all of these goals — enabling millions of dollars of cutting edge research, supporting thousands of users, expanding its testbed capabilities, and more, while at the same time bringing together various efforts to create a broader constellation of projects and users.[2]

Fig. 3: OpenInfra Labs, the newest OpenStack Foundation pilot project
Problems
A number of challenges arose from the MOC’s early adoption of open source software to create a public cloud. Self-service user management — which includes, for example, onboarding and offboarding of users across multiple software projects (OpenStack, Kubernetes, Ceph, etc.) and centralized quota management — requires reconciling how different software projects define users and projects.
Another challenge is reporting. Take a simple report template (italics are variables), for example:
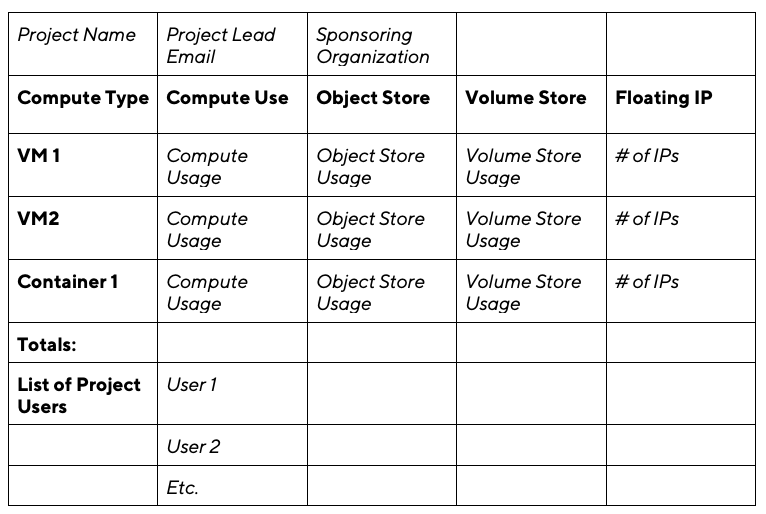
This presents the self-service user management problem in reverse, since usage, how information is stored, and where the information is stored are handled differently by each software project. Additional changes may be introduced by updated versions of software.
Similarly, a single dashboard for monitoring that includes services like OpenStack, Kubernetes and Ceph does not come “out of the box” and requires integration. Ideally, having solutions for the monitoring you need during the rollout of a new cloud (Day 1), regular operation (Day 99), and including monitoring based on best practices that others have learned from running clouds over years (Day 999) would have been incredibly helpful.
Recognizing these problems was the first step, yet problems for operators still remain. Open source projects tend to be focused on solving specific problems rather than integrating into a unified cloud solution—the open source community scratches its own itches, which generally do not include deploying a cloud and charging for it.
Solution
The MOC spoke with some of its core partners and heard similar pains. It seemed everyone was in agreement that there was a need for a place to identify user stories that cross project boundaries, a group that could share solutions, and a place to capture successful recipes for different types of clouds — they needed a community of operators.
From there, the MOC spoke with the OpenStack Foundation (OSF), and both parties quickly realized that they were grappling with the same issues. Open infrastructure today requires integrating many open source components, such as OpenStack for cloud services, Ceph for storage, Kubernetes for container orchestration, and TensorFlow for machine learning. Each integrates with, relies on, and enables dozens of other open source software projects. This many-to-many relationship poses an integration challenge that can make open source options less attractive than proprietary choices that are more turnkey.
The MOC and the OSF saw an opportunity to leverage not only each other’s experience and expertise, but also to collaborate to create a broad community focused on integration and operation of open source clouds.
Since its launch, OpenInfra Labs has been focused on creating repositories to capture successful cloud implementations that others may replicate, reaching out to the larger community, and integrations with tools that operators may find useful such as the MOC integration of Adjutant for onboarding. Over time we envision the repository hosting many flavors of opinionated cloud stacks and tools.
In addition, OpenInfra Labs hosts several related initiatives:
- The Operate First Initiative: making cloud operations as fundamental as functionality in upstream projects.
- Project Caerus: improving coordination between compute and storage systems for big data and AI workloads. Read the Project Caerus Manifesto.
- Elastic Secure Infrastructure (ESI): enabling infrastructure to be securely provisioned and moved between different services. Visit the ESI project page.
- Project Wenju: Simplifying the development and operations of enterprise AI systems to achieve value from AI more quickly. Read the Project Wenju Manifesto.
Whether you are an operator, developer, hardware provider, cloud partner or funder, the OpenInfra Labs community is eager to involve new participants. More information at https://openinfralabs.org/.
Conclusion
Along with presentations by Blizzard Entertainment, Verizon and OpenInfra Labs, the OpenDev event also included perspectives from users at CERN, China Mobile, VEXXHOST, StackHPC, and more. One of community members’ favorite aspects of events like OpenDev is the opportunity it gives them to share stories, ask questions and initiate external groups to facilitate collaboration on a wide variety of open source projects. To get involved in this community by hearing stories firsthand and/or sharing your own, join us at any of our events listed here.
Author:

Allison Price
Senior Marketing Manager at the OpenStack Foundation. Allison manages marketing content initiatives including case study development, advertising campaigns, the Superuser online publication and OpenStack User Survey. Her past roles have specialized in social strategy and execution for both B2B and B2C global companies in the technology and consumer industries.
[1] If you’re interested in finding solutions to these challenges, Blizzard is hiring at their offices in Irvine, CA.
[2] For more on the Mass Open Cloud and its connected initiatives, visit www.massopen.cloud