Interview with Kim-Norman Sahm
Kim-Norman Sahm is Head of Cloud Technology and Chief Evangelist at Cloudical and an expert on OpenStack, Ceph and Kubernetes. As a typical Ops-Guy he is in Storage at home and has already implemented several Ceph projects. Storage options and capacities have always played a major role in the IT environment, but with the move into the cloud these options are changing a lot, how they are changing and how Ceph can be integrated, we got to the bottom of this interview.
Why is storage important? What is special about storage in the cloud? What has changed?
Storage has always been a topic, in the legacy world there were the requirements to store all the information that arises. All apps were dependent on having persistent storage available. In general, storage and compute resources were handled very generously. Even for the smallest applications, too large servers were often purchased, 90 % of which normally remained unused. Systems were inflexible and divided into monolithic storage blocks. There were few storage vendors and the offerings were often very expensive.
Over time, it evolved towards using resources more efficiently, both compute and storage. Virtualization was seen as the solution to use compute resources more efficiently. The storage sector has changed to SDS solutions (software defined storage), which offer a multitude of ad- vantages: cost efficiency, flexibility, elasticity, … Software solutions break down the hard limits of classic storage solutions and make distributed systems possible, georedundancy and, for example with Ceph, avoid vendor lock-in, the storage system is no longer dependent on one manufacturer. In the cloud storage has become a service and customers only want to pay for what they actually use. This also has advantages for the provider, who can use storage flexible and efficient.
In the case of Cloud Native applications the mentality has also changed to the effect that only what needs to be stored is stored, not everything. The majority of microservices, for example, are stateless, no more data is stored. So the storage is also used efficiently in this respect.
“A big advantage of Ceph is that it provides block,
object, and file storage from one Backend.”
How does Ceph work?
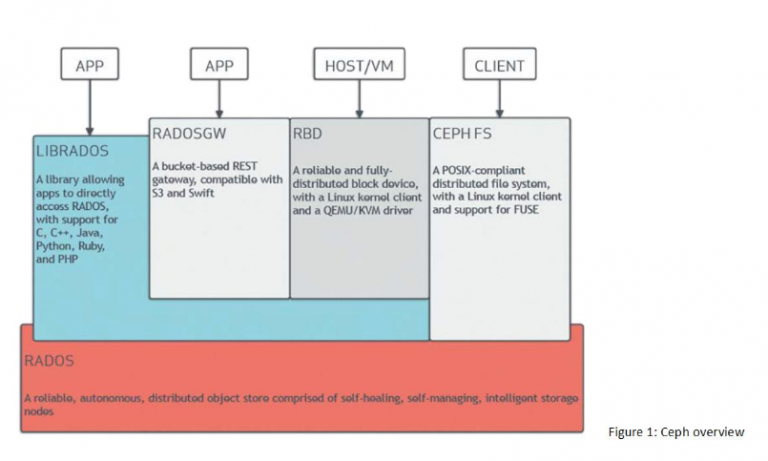
When the Ceph project was started, the offer was limited to block and object storage. Compared to other storage solutions that connect the client to the storage system via gateway or proxy nodes, Ceph introduced a „no single point of failure“ right from the start. The Ceph architecture initially consisted of Ceph Monitor (Mon) and Ceph OSD (Object Storage Daemon).
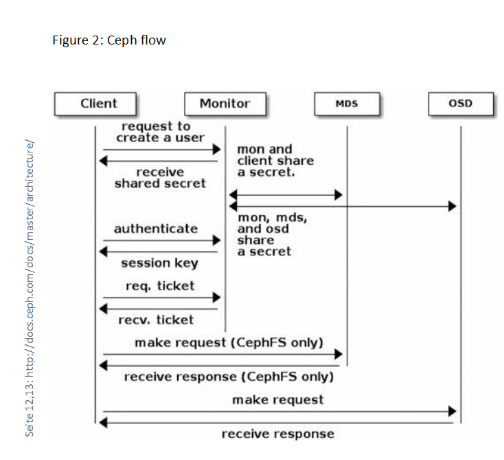
Mons provide the cluster logic, there must be at least 3, maximum 11 monitors in the cluster, the number of which must always be odd because of quorum. The task of the Mons is to monitor the cluster state and ensure the highly available distribution of the objects. The Mons hold the CRUSH map, a kind of map of the objects, for this purpose. The actual user data is stored on the OSD nodes. An OSD always represents exactly one physical hard disk. When a client wants to access the block storage data, it first contacts one of the monitor nodes and requests the CRUSH map. Using this map and the CRUSH calculation algorithm, the client is able to independently calculate which OSDs contain the data it needs, and then directly contacts the appropriate OSD nodes (figure 2).
If data is written, the system behaves in the same way. To ensure high availability objects from the Ceph cluster are replicated three times (Ceph default value). One object is written, but then exists three times in the cluster. The replication level can be adjusted, but there is a balancing act between high availability and cost efficiency. The special feature here is that the write process is not confirmed to the client until all replicas have been written. This, however, represents a difficulty when setting up geoclusters, because the packet runtimes can lead to problems. Therefore, there are no Ceph geoclusters. The Ceph project is currently working on asynchronous write operations, among other things, in order to make this possible.

A big step forward was made for the Ceph project when the OpenStack community became aware of Ceph and this is an excellent backend for OpenStack Cinder (Block-Storage) as well as a replacement for OpenStack Swift (Object-Storage). This development helped Ceph to a higher market share, as Ceph is still considered the standard storage backend for OpenStack. To complete the trinity of storage, Ceph introduced CephFS, a network-based file system, the client module of which has been version 2.6 in the Linux kernel.
“With its high scalability, Ceph allows you to start with a small setup”
Why is Ceph used? What is it important for?
Due to its versatility, Ceph is suitable for many companies. With its high scalability, Ceph allows you to start with a small setup and grow it as your request/use grows. Whether as a pure object store for backups and other applications, as a backend for private cloud solutions based on OpenStack or KVM or as an NFS replacement for Linux clients, Ceph can be used flexibly. Due to the good integration in Kubernetes, Ceph can also be used in the container world.
In most management rounds, the main argument for introducing Ceph is the price advantage over commercial closed source enterprise storage solutions. Cheap server hardware and community software enable a start with low capex costs. Those who have sleepless nights when using open source software with community support have the opportunity to purchase commercial support via Linux distributors.
The Subscriptions model is thereby very differentiated and should be thoroughly examined in advance. In general, as versatile as Ceph is, the greater is the challenge in day-to-day operations. The Ops team has to be fit.
Source:
– http://docs.ceph.com/docs/master/ architecture/
Interview by Friederike Zelke / Cloudical