Before software is handed over, it is tested. Before you run it, you want to be sure it‘s doing what it‘s supposed to. But the more agile the process becomes and the more automated it becomes, the faster software is deployed, the less space there is in the process for test- ing. this article shows how testing can be integrated and planned into the agile process from the beginning, so that high-quality results can be delivered.
Software systems are usually constructed so that their function is spread over a set of coupled components. Then, that set of software components forms a logically dependant, but technically isolated, composite, which in it’s entirety forms the application. Such a modular construction of software systems has been an accepted industry standard for some years now and has been grown to new complexity, some might say extremes, with the advent of micro-service architectures.
Adding to the complexity of (multi-tiered) software, application software relies on a number of backend systems behind the application’s “actual backend”, i.e. auxiliary software (message brokers, backup, logging, monitoring) and infrastructure components (that stuff that the application actually runs on, viz. computers, networks, storage systems); and it is – by and large – undisputed that application software cannot run without it(1). For these, distribution of components is de-facto mandatory.
Distributed Systems
Such distributed systems are, while not exactly fragile, still complicated and leave copious space for errors.(2) To reduce the probability of such errors hitting production, software development processes stress the importance of quality control, often called testing. Before a given piece of software will reach production, it has been subjected to a multitude of unit, integration and acceptance tests – all at different abstraction levels. These tests are, because developers are very fast at producing errors, themselves software. And, as we all know, software can, as anything computerized, run faster, more often, at times when developers sleep, etc. So, in theory, the testing stays ahead of the developers at all times. In practice, it doesn’t, and software development has coined a less aggressive sounding word for such errors, “bugs”, to save themselves from the embarrassment.
Administrators, operators or whatever the current term may be, do not err when deploying or maintaining; accordingly, they do not need to resort to insectoid imagery and certainly do not need to automate away the testing.(3)
Classical, manually administered environments
Those that work and do not break with any new release – distinct themselves from software development and it’s methods of verification and testing, and the speed of producing errors anyway. To guarantee the correct setup and accordingly, the specified functionality of a computing environment, so-called “changes”, i.e. alterations to the systems, are “transported” stepwise over a number of increasingly more production-like pre- production “stages”, where any errors, should they occur, can be caught. Correctness is given when testers run and analyze a set of tests and they return without error – the tests, not the testers.
This practice has spilled over to automated, “neo-classical” environments, where, even if the mechanics of deployment have been passed to an automaton such as Puppet or Ansible, the proven practices of performing changes have stayed more or less the same.(4)
With that reasoning understood
According to that, unsurprisingly, testing and software testing alike is all but common practice for infrastructure systems and their guardians. Although the “underlying” infrastructure or auxiliary software and systems comprise non-trivial portions of application function, when verifying and testing an application, they are largely ignored.(5)
However, such an approach to operations is generally and increasingly unfit for a dynamic setting: When autom- aton rapidly perform scaling and replication or re-provi- sion software systems to other computers autonomously, entirely without human intervention, the approach of pro- visioning and testing over pre-production stages cannot keep up with the speed, the agility of change itself. Be- cause operating untested software is a Bad Thing™ – and prohibited in regulated environments such as finance any- way – automation should generally not be trusted with the operation of professional IT.(6)
Unfortunately, they re-invented MULTICS lately, called in air-mobile cavalry of supreme marketing, christened that “the cloud” and, alas, managers aspiring to get honorable mentions in Gartner reports or whatever gossip & glamour magazines the so-called working, so-called professionals consume, demand their IT organizations to use and to operate cloud services.(7)
Speed in dynamic settings
In this inherently dynamic setting, resources are provisioned rapidly and on demand and are decommissioned when no longer required, and because of the speed at which these operations need to be performed to be useful, they require a high degree of automation, all of which is code in some aspect or the other. Administrators are thus forced to look into the cloudy skies instead of keeping their focus firmly on the ground and now, they produce errors at the same dangerous rate developers do and are used to do. To add insult to injury, they have lately introduced orchestration middleware such as Kubernetes to IT operations. By this cunning scheme, cloud wobbliness has taken over in-house operations. Why build roofs, when you like rain so much? In this context, administrators might, even with some remaining nausea, look at how developers have managed to live with change, which has has lead – with varying degrees of success and satisfaction(8) – to the DevOps idea of actually introducing development methods into the operation of IT systems.(9)
Automated Testing
When automated or even autonomous systems, which are themselves defined by code, provision and deploy, then the deployed infrastructure itself is defined by code. Such code will then be developed like any other software component or system, and development methodology may – should – be applied. This includes testing, and, more specifically, such infrastructure code should then be sub- mitted to the same automatic tests (software by itself) to demonstrate it fit to the specification.
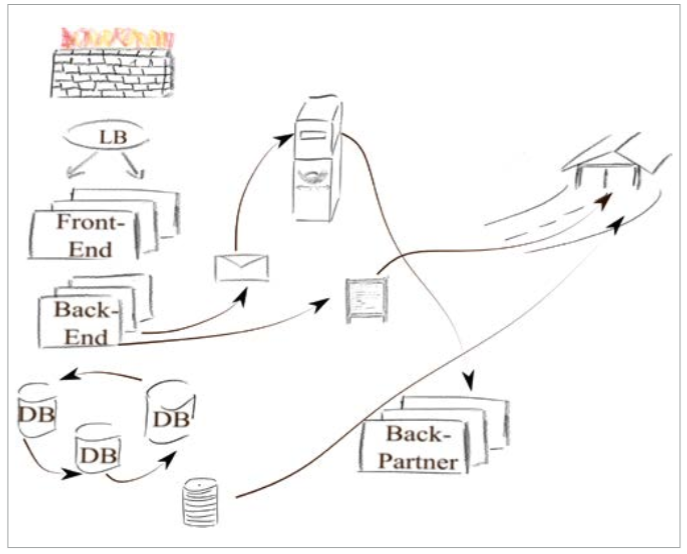
Figure 1: Distributed Systems
Reasoning thus, when operating rapidly changing infrastructure and auxiliary systems, either cloud or cloudlike in-house middleware, methods of development and operations converge, and automated testing should be introduced to the operators modus operandi.(10) Having thus been convinced – or coerced – that dividing between infrastructure, auxiliary and application systems is rather artificial, it may be time to revisit infrastructure from an application’s point of view.
Persistent Storange
Most applications rely on storage systems, often databases, but, depending on the application domain, also large object stores or buckets of files. No-one actually would argue against persistently stored state being integral to the function of many applications. Cloud or no cloud, professional storage systems can reasonably and well be trusted in so far as they do not loose data, but their correct configuration cannot be blindly assumed.
The permissions governing the access to data could well be wrong.(11) Performance may rely on correctly spreading the load over a number of participating systems, which nobody really
checks. Resilience relies on redundancy,(12) so distributed databases claiming to survive the loss of one or even many nodes should really be distributed instead of being strike through smeared over only a subset of machines with the rest of ’em happily idling – contributing to the power bill, but not to the required failover properties of the system.
Often, applications write journals of logs
Logs are often of a technical nature, sometimes even purely so, but sometimes, they already have or later gain a business relevance up to being part of a mediation system. Then, their retention and deletion may well fall under different laws governing trade and taxation, making their correct handling much more compulsory instead of errors being a mere nuisance.(13)
Conversely, under European data protection laws, certain data may well be subject to a maximum retention time and accordingly, must be periodically deleted. Failure to do so not only may but will result in severe and punitive penalties. Even without GDPR-effects, failure to timely delete some data may be even more punitive: No law enforcement agency can sub-poena data to be handed over which, legitimately and in compliance with the relevant laws, has been deleted with their retention period long past.(14)
Even so, retention and deletion in databases and archive systems seldom are of concern to the application, seldom are they tested as relevant parts of application function, instead, the corresponding tasks are delegated to operations as the cleaners and janitors of IT.
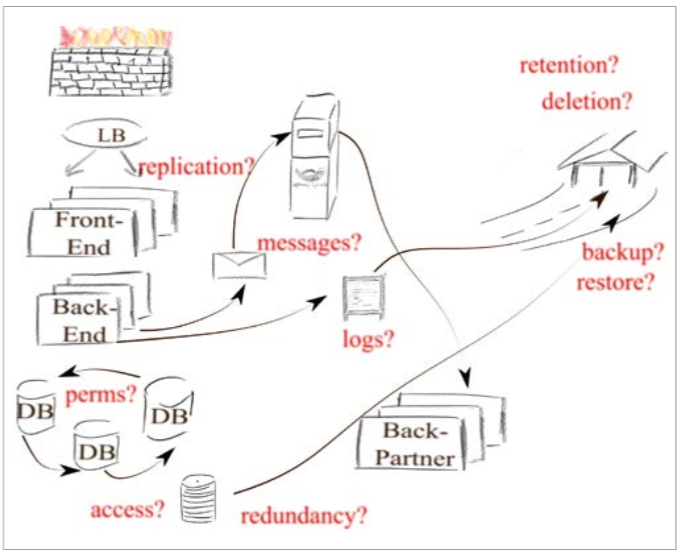
Figure 2: Automated Testing of Infrastructure Components Considered Harmful.
A possible propagation, no, proliferation, of data to a set of (on- and off-site) backup systems should be, by the same reasoning, tightly controlled. Yet, most are blissfully oblivious to the toxic waste lurking in the depths of the enterprise data vaults, not just waiting but rather begging to be discovered by law enforcement at most untimely moments.(15) Yet again, punitive as it may be to mess up retention or deletion, where and in whose stewardship data may end up before it is forgotten usually is not part of application testing.
Dynamic Operations
In this respect, dynamic operations – wether cloud or non- cloud does not matter – are a game changer! While we may – successfully or not – have sat out the necessity to prove or at least verify the correctness of infrastructure and auxiliary systems regularly, when dealing with highly distributed, highly interdependent and rapidly moving systems, we simply cannot.
With automagically(16) redeploying, redistributing, re-provisioning infrastructure components, transporting over stages does not work and adaptions to production are made without testing in pre-production first. The frequency of changes will be high, and errors will be made, to err is human, after all, and the frequency of errors will initially correspond to the frequency of provisioning.
So, principally, after every change the automaton intro- duces, the stack should be tested, and with much sighing and occasionally, fainting, we accept the inevitable of automated testing. We may speculate on the wee hours in the night when we, for a short time, may skip some tests, but, conceptual, testing event driven requires more adaption than just counting the ticks of a clock, it may be easier just to test periodically. Then, conceptually, testing and monitoring start to converge.
The outrage (“No! We do not test in production!”) starts to become bearable (“Yes, certainly we do monitor our pro- duction, mind you, it would be insane not to!”) and sudden- ly, we realize, that, even if the factors driving development and operations may be different, the aims are not and, in the end, similar tasks are performed by very similar means. Then, the engineers operating dynamic infrastructure – may they call themselves Platform, Site Reliability or Oper- ations Engineers – will soonish have monitoring or testing – again, the naming does not matter – suites in place, which will close the gap of application testing to include the infra- structure and the auxiliaries. Only this I cannot imagine: Calling it “Test Driven Opera- tions” – that would probably have problems to be accepted.(17)
footnotes:
1 The usual suspects have been waiting to divert the discussion to λ all along, but neither kidnapping Alonso Church nor enlisting the help of μ, ν or members of other alpha- bets may bend the fact that irrespectively, that stuff still needs to run somewhere.
2 Some call them beasts, and while this sometimes may be true, more often than not the beasts are long dead and their decomposing carcasses form a swamp which may kill the unsuspecting just as efficiently, albeit slower, as the beasts themselves could, when they still were alive.
3 At 120kg and just a flight of stairs away from a halting cardiac, administrators are a dignified folk and not so fast at producing anything, which includes errors, mind you, and have, by the way, understood the recursion problem with so-called software testing finding software errors and, accordingly, do not even try to accomplish the impossible.
4 I.e., find some machine in the development stage, perform the change, prod it to find out if it is strike though effect still alive, resurrect it when dead by fate of chance and gradually reduce the prod-resurrect iterations to zero till production.
5 We may now debate if the term “underlying” still fits, when the contribution to an applications’ function is non-trivial, which we won’t, because IT professionals are too ex- pensive as it is, which is a problem in itself and won’t be helped by declaring the janitors and cleaners important parts of an enterprise. Issue closed, thank you very much.
6 Anything remotely resembling opposition is quickly killed off casually pointing out the algorithmic difficulties for any automaton to correctly select the proper type of ITIL change and actually get it approved in this eon. QED.
7 Oh my gosh! Blimey!
8 Und wenn du lange in einen Abgrund blickst, blickt der Abgrund auch in dich hinein. (And if thou gaze long into an abyss, the abyss will also gaze into thee.)
9 If the DevOps idea of increased collaboration between developers and operators has lead to successful advances or even is on the right path requires large amounts of beer and even larger amounts of time, which in turn requires more beer, albeit without significantly increasing the chances of timely resolution …
10 When advocating testing, we implicitly admit the possibility of erroneous infrastructure provisioning, which we earlier have convincingly ruled out. Combatting the resulting cognitive dissonance with even more beer – settling at a bottle per page – and assuming enough experience in the industry, we may reach the unsettling conclusion that the time- and battle-proven approach of testing deployments over stages has some faults indeed and, in fact, some errors reach production, but …
11 In 2017, the Swedish Transport Agency or their contractors, it does not matter in terms of responsibility or the lack thereof, mistakenly leaked the witness relocation program from publicly accessible AWS S3 storage buckets. Don’t drink and strike though deploy!
12 Never ever misconfigure a RAID. Never ever!
13 A premature data loss possibly leading to an estimation of undeclared revenue von Amts wegen is entirely different in terms of gravity indeed when compared to a loss of some random logs.
14 Lessons well learned by the financial services and automotive industry with agro-sciences yet to join the party.
15 The more technical versed are untouched by such perils: Any connoisseur of enterprise IT well knows that backup may be tested, but data restore procedures almost certainly never are. The probability to successfully restore data is a function of time, decay rates and the fact that after a certain amount of time, the archaeologists of IT are required to decipher whether these glyphs over there have been a legitimate file format at some time, or just droppings left behind by marauding hordes of rodents.
16 Walle, walle, manche Strecke … (Quote: Der Zauberlehrling Johann Wolfgang von Goethe)
17 In DevOps, we gamify operations. Two outages, and Ops-Team is out. (DevOps Borat)
Author:
Christopher J. Ruwe
Dipl.-Kfm. u. M.Comp.Sc.
Systemanalyse und –beratung
Christopher J. Ruwe (1982), having studied Business Administration, decided afterwards that learning something actually useful might have been more sensible.
Having then added Computer Science at FernUni Hagen to the mix and consulting as DevOps-Engineer or rather System‘s Archaeologist, professional gardening might prove an even more sensible choice. One could grow roses …
https://www.cruwe.de