If you want to use the possibilities of reliability and scalability in IT landscapes, this is easily achieved by Kubernetes ecosystems, which you can set up with a cloud service provider or in your own data center (on premise). This article describes how to roll out applications in a Kubernetes ecosystem, which tools you need, which “middleware” is necessary and which cloud service providers (hyperscalers or GDPR-compliant service providers) you can use.
Cloud Technology also in Germany
Almost 10 years ago I wrote an article “Governance and Compliance in Cloud Computing“. At that time, I concluded that clouds could be used, since US ministries were also putting their mails in the cloud with Google and Microsoft, and Dataport in Hamburg had successfully tested the code of Microsoft365 in order to use it in their own private cloud in compliance with data protection.
But the BMWi got in the way by blocking the market in Germany for five years with the Trusted Cloud project. Today it operates as an association (Bundesdruckerei et al.) and no longer disturbs the market. Instead, cloud use has spread massively, initially through hyperscalers from the USA and China, increasingly through European providers.
Here I give a brief overview of how cloud strategies can be developed technically. The figure gives an overview, which will be discussed in detail below. Three levels can be seen here.
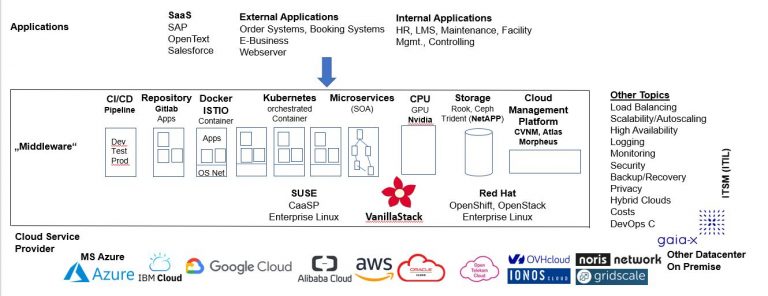
Level 1 Application Level
In the application level you find:
- Software as a Service such as SAP, Open Text, or Salesforce, which can be booked ready-made in the cloud.
- Application for external users: Own existing applications can be order systems, booking systems (airline, railway), other e-business systems.
- Internal applications can be HR systems, learning management systems, maintenance systems (machines, vehicles), facility management systems, controlling etc.
- Self-programmed applications can be integrated e.g. as microservices via own CI/CD pipelines.
Level 2 Cloud Level “Middleware”
This layer is intended to provide scalability and resilience to a Kubernetes ecosystem. Initially, programs are loaded from repositories and deployed in a container (Docker or Istio).
Kubernetes then manages the individual containers. For example: start three identical containers in the morning, which you then load evenly via a load balancer. In the peak times of user demand, add three containers more. Logging is important here to see whether my assumptions prove to be correct. If I have too few containers, there will be waiting times; if I have allocated too many containers, I am paying too much to my provider. With efficient scaling through the load balancer, unnecessary costs can be saved here.
Storage must be provided outside the containers (Rook, Ceph, Trident, S3, etc.) to keep the data persistent and to synchronize parallel instances. Containers themselves do not store data and lose all stored run data when they shut down.
A CI/CD pipeline (development, test, production) can be used for in-house development with Ansible or Jenkins. Own binaries can be loaded into a repository (e.g. Gitlab) like foreign binaries in order to load programs from it at container start time.
For computationally intensive processes, graphic processing units (GPUs), e.g. Nvidia, can be integrated into Kubernetes ecosystems.
These elements are all set on e.g. commercial software from SUSE or Redhat or on open source software like VanillaStack. In VanillaStack, for example, all the listed tools are included as open source.
Other Topics
On the software side, there are also programs for load balancing, scalability/autoscaling, high availability (e.g. two remote data centers with data mirrored in real time), monitoring, backup/recovery. The following should be emphasized:
- Security: Who is allowed to access software how? Do I use NAT (Network Address Translation) to protect other computers? Reverse proxies? Firewalling?
- Privacy: In Germany, it is very important to comply with the GDPR when processing personal data (not IoT data without personal reference). US hyperscalers cannot adequately comply with this due to the Cloud Act, in which the US government forces US companies to hand over personal data in the European jurisdiction against European law.
- Costs: Cost structures can be complicated. E.g., pre-ordered nodes vs. allocation on demand, have the pre-ordered nodes really been used? Therefore, monitoring for cost control is eminently important with variable costs.
- Hybrid clouds: as an example, it can be important to use clusters at a cloud service provider for the CPU load and to use existing storage devices in existing data centers for data storage. It may also be that you want to use investments in your own storage systems for a longer period because you cannot or do not want to take the systems with you into the cloud data center.
- Scalability/autoscaling: It is important to have an ecosystem that scales according to load. This can be fixed or can also be done automatically according to the actual load of the nodes, e.g., triggering the automatic addition of further nodes from 75% load.
Special cases
The above describes how to use “a” cloud, there are additional cases:
- Resilience/mirroring: here you have to decide whether you want to mirror your architecture at another site and at what level the mirroring should take place. For example, a database mirrored in real time, the two working in parallel via load balancing or whether, in the event of a failure of one system, the other should take over.
- Edge computing: here, for example, many autonomous systems can be widely scattered at the “corners” of the cloud, collect and (pre-)process data locally and then transmit it centrally because you want to generate commercial invoices from the technical data. Decentralized processing at the corner can save bandwidth.
- Multi-cloud: it may be that data collections are to be used by several organizations. For example, according to Redispatch 2.0, energy suppliers must switch off their coal-fired power plants when there is enough wind and solar energy. For this, of course, you want to know very early on from shared data whether there is enough energy from sustainable sources in the grid.
Level 3 Cloud Service Provider
Once you have a plan for implementing your application landscape in the clouds, you need a cloud service provider. There you will find Microsoft Azure, IBM Cloud, Google Cloud Platform, Alibaba Cloud, Amazon AWS, Oracle Cloud, whereby the US hyperscalers are not usable due to the Cloud Act for personal data without GDPR compliance. European providers such as OVHcloud, noris network, Ionos Cloud have no data protection issues and can therefore be used for personal data in Europe.
The cloud service providers that are GDPR-compliant will probably be found at Gaia-X from the beginning of 2022. There you will be able to say in the catalogue: I need 30 nodes, this much memory and this much storage. You will then get a list of certified providers and also prices, which will boost competition.
Conclusion
The cloud age has also dawned in Germany. Not only large companies, but also the Government and small and medium-sized enterprises can use cloud technology cheaply and securely, even within the European legal framework with GDPR. The explanations show that the use is not entirely trivial and that applications and infrastructures should be better separated in the IT departments, but many of the tasks described above can also be partially automated today. However, these developments also mean relief for organizations whose core business is not IT operations, i.e. most.

Wolfgang Ksoll – Cloudical
wolfgang.ksoll@cloudical.io