CI/CD stands for Continuous Integration / Continuous Delivery and depicts an approach where software is built and deployed whenever a check-in into a source code repository is executed. This allows for a central build process, central storage of generated artifacts and centrally executed tests. The idea sounds simple, understandable and obvious. But it isn’t, at least not from an executional point of view, since there is more to it in modern application- and cloud-native environments.
Traditional idea behind CI/CD
Traditionally, CI/CD processes evolve around the concept of building, testing and deploying centrally. Usually, CI/CD platforms such as Jenkins are utilized for this, in mid market and more enterprisefocused environments dedicated engineers are setting up the environment and create triggers inside a source code environment. An integration with JIRA and Confluence is created.
Typical minimal requirements to a traditional CI/CD pipeline are:
– Code is created once and only once
– Generated Artifacts are to be stored in a repository within the system
– Generated Artifacts are to be tested using unit tests
– A build and testlog has to be created
– The status of a build needs to be documented within the system
A typical approach for a CI/CD pipeline using Jenkins would look as depicted in figure 1 – source code is checked in, a trigger is executed, code is built, some local tests are executed, and an artifact is stored.
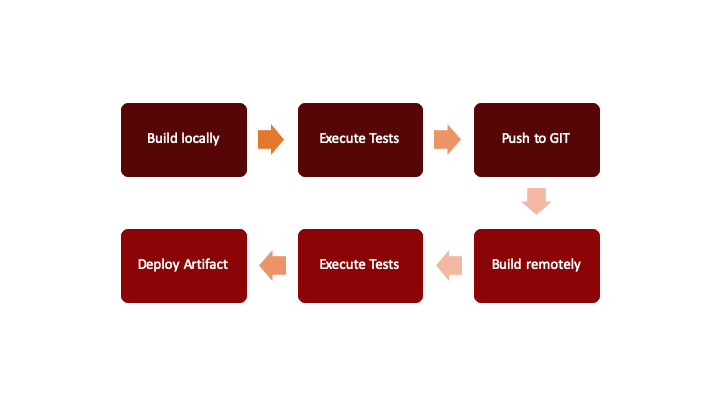
Fig. 1: Schematic view of a traditional CI/CD pipeline
This approach is understandable, simple and works. But it is not enough for a cloudnative world, where building and creation of artifacts are just one step in a more complex process.
Idea behind CI/CD in cloud-native environments
Within cloudnative environments, a CI/CD process is basically looking the same as in traditional environments, but complexity, challenges and count of steps within such a process are increased.
The reason for this is the environment per se: A cloudnative environment usually consists of more components to be built and maintained. Since such an environment is set up for scaling and 24/7 availability, therefore security and codequality requirements are not comparable to traditional approaches. The build and testenvironment need to be scalable as well, it needs to be able to be commissioned when required and decommissioned when not needed anymore. Unfortunately, this still is not enough in regard to requirements and complexity, since a different vector is adding even more challenges to the game: trustworthiness.
Trustworthiness
Since cloudnative applications are designed to scale and to be rolled potentially out on a worldwide level and within different cloud environments, they need to put a focus on embracing trustworthiness.
This implies more complex requirements to a build process:
– Code is built once, and only once
– No binary external dependencies are to be used
– No unchecked container images are to be used
– Generated Artifacts are to be stored in a repository within the system
– Generated Artifacts are to be tested automatically using unit tests
– Generated Artifacts are to be placed inside containers
– Generated Containers are to be stored in a container registry within the system
– Generated Containers are to be deployed onto a test environment
– Generated Containers are to be tested automatically
– A build, containerization and testlog has to be created
– The status of a build needs to be documented within the system
Just by reading these requirements, it gets obvious, that a CI/CD pipeline fulfilling them would look way more complex than its traditional counterpart, would be more challenging to set up, would consume more resources and would need to be maintained differently, since more and different components are involved.
For this reason, such a CI/CD pipeline is typically not maintained by a dedicated engineer alone, but by the development team. Within a cloudnative environment, there is still an expert for the CI/CD platform of choice required, but the broader and more restricted nature of it would require a teameffort and a joint contribution, in stead of simply consuming and utilizing a pipeline being provided. Figure 2 shows a schematic view of a cloudnative CI/CD pipeline.
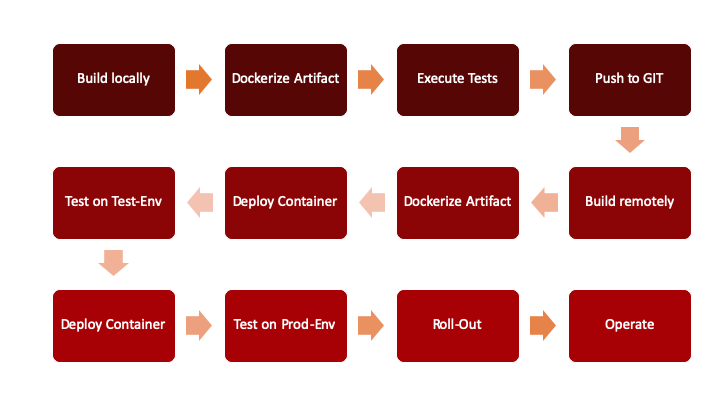
Fig. 2: Schematic view of a cloud-native CI/CD-pipeline
Which CI/CD-tool to choose on which platform?
One of the most often asked questions when discussing CI/CD pipelines, is which tool to choose in which platform. Generally speaking, there is no such thing as THE answer to this question.
All of the Hyperscalers (AWS, Azure, Google Cloud) have their own CI/CD functionalities, which are aimed at providing a seamless integration with the underlying platform. These platforms are not free, even if they provide a free tier. Compared to having set up a dedicated CI/CD pipeline on the respective platform, the relative costs can vary from being cheaper than hosting a dedicated CI/CD account to more expensive – usually this is depending from the number of build processes and the performance required.
Let’s have a short look at the offerings:
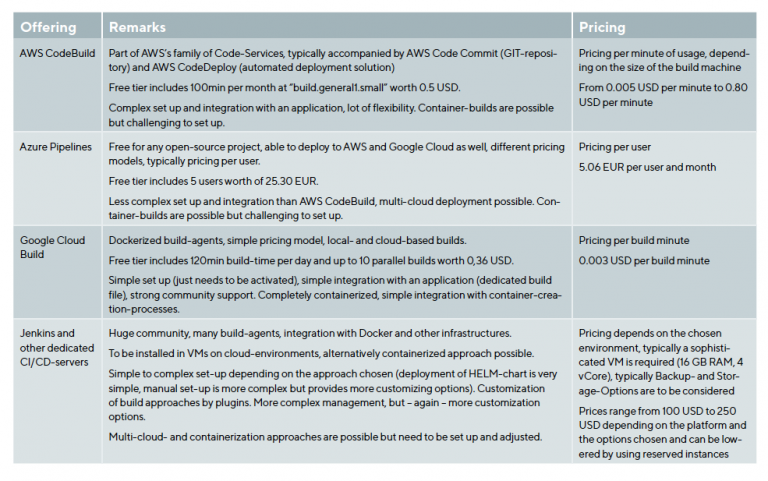
Based on this information, some recommendations can be given:
a Understand your requirements, since they define the best possible solution for you.
– For an easytosetup and use CI/CD solution, Google Cloud Build would make up for a good choice, especially when looking at containerized workloads.
– For multicloudapproaches and more traditional applications, Azure Pipelines would be a good fit, especially since five monthly users are part of the free tier.
– For a 24/7 environment, customized to the organizations own needs, integrated into their infrastructure and softwarestacks, Jenkins or other dedicated CI/CD platforms would make sense.
Integration with PaaS-services
All CI/CD pipeline offerings allow to deploy the generated artifacts and / or containers. This might sound feasible for bringing applications into a productive environment, but it is not enough for operating them. At this point, PaaS solutions, such as Cloud Foundry or SUSE Cloud Application Platform enter the stage, since they not only deploy work loads, but run and operate them within given boundaries, ultimately freeing up human resources.
Such PaaS services start from a deployable artifact or container. This defines a natural boundary between CI/ CD solutions and PaaS offerings, where a CI/CD solution would be responsible for creating an artifact and a PaaS offering would then run the artifact. Figure 3 shows the schematic approach.
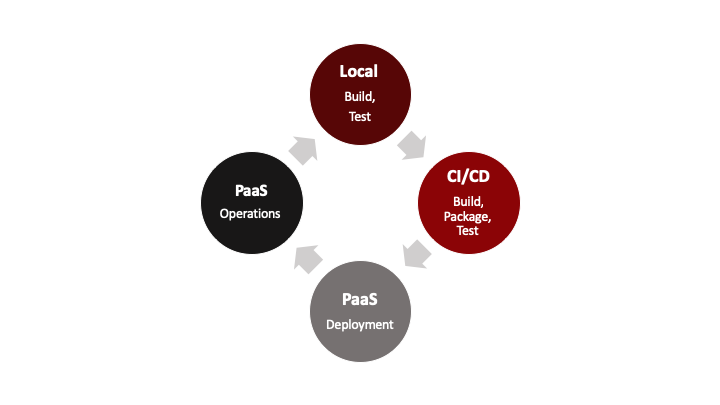
Fig. 3: CI/CD and PaaS
Since an artifact is created by a CI/CD pipeline and a PaaS solution simply pushes an artifact into production, the integration between the two components is very straight forward: typically, the last step of a CI/CD process would be the call to the PaaS solution for deploying the given artifact, which is most often as easy as executing a cf pushstatement on the commandline. From there, the PaaS environment would take over and at this specific point, any responsibility from a CI/CD environment would end.
Additional tools and frameworks to consider
Since the quality of an artifact and / or docker image being brought into production heavily depends on it having been extensible tested and codereviewed, additional tools and frameworks are most often bundled with a CI/CD process:
– CodeAcceptanceTools for manual review, such as Gerrit
– CodeQualityTools for automated code review, such as Sonaqube
– Automated Frontend Testing Tools, such as Selenium or Jasmine
– An artifact repository, such as Artifactory or Nexus
– A docker registry, such as Harbour
The list could continue endlessly… The most important factors when choosing any additional tools has then again to be the requirements. Therefore, it is very important to define any requirements upfront and to choose a tool stack which is working for the team, the project and the ecosystem.
When to start with CI/CD?
Often, teams start by writing code and by building manually. They want to have “something ready”, CI/CD processes are understood to be complicated, complex to set up, limiting and as something, which could be added later to a project.
Problem is: The longer a project is being worked on, the harder it becomes to integrate it with a CI/CD pipeline and the more “disturbing” any kind of integrational efforts are anticipated.
Experienced teams start by defining a simple CI/CD pipeline, just providing the basic functionalities and grow it from there – basically applying the same mindset to their infrastructure as to their code. This allows for a relatively soft start with minimum overhead, a simple environment and more confidence in quality from the start.
Therefore, the best point in time to start with setting up a CI/CD pipeline would be literally in the moment, when the first line of code is written and checked into the sourcecode repository. Later would complicate things a lot, earlier would be theoretical and would possibly not fulfil expectations.
Conclusion
CI/CD in cloudnative environments is different in execution and complexity when compared to traditional environments. Several options for setting up and running cloudnative CI/CD solutions exist. Choosing one over the other has to be done based on requirements, addition al softwarestacks needed, integrational aspects and the level of customizability expected. CI/CD solutions do not necessarily need to be expensive; the most expensive aspect is not an infrastructure being used or an environment being chosen, but the integration into a team’s development process and with the software being developed is the main cost factor. Therefore, it is advisable to start with the process of setting up and tailoring of a CI/CD pipeline as early as possible in the development lifecycle.
Author:

Karsten Samaschke / CEO Cloudical Deutschland GmbH