Open Policy Agent (or OPA, pronounced Oh-pa!) is an open source, general purpose policy engine. Breaking that sentence apart, “open source” and “general purpose” likely won’t need further explanation for this audience, so let’s jump straight to the “policy engine” part.
At its core, a policy—in the “real world” and in OPA—is a set of rules. These rules most often dictate whether something or someone should be allowed or not, but could just as well be more nuanced. Some examples of rules might include:
- Any doctor should be allowed to see the medical records of their patients.
- A user that logs in to do administrative tasks should only be presented options relevant to their role.
- A new software deployment must only be allowed if deployed with a minimum of two replicas.
- Any micro service must not be allowed to communicate outside of the cluster.
- Infrastructure deployed in cloud environments must always have appropriate tags to show who is responsible for the associated resources.
- Only someone who has authenticated with more than one factor (MFA) should be allowed to view credit reports.
Historically, policy rules like these have commonly revolved around authorization (i.e. who and what gets to do what). With infrastructure, build and deployment pipelines and software defined resources increasingly being defined as code, policies have however found both new use cases as well as a wider audience. This change is embodied in the movement commonly referred to as “policy as code”. Let’s take a look at what that entails!

Decoupling Policy
When reading the example policy rules above, many of you will probably think, “hey! I’ve written such rules in my code before!” And you’d be right. Embedding policy rules inside of application and business logic has traditionally been how policy made its way from PDF documents and PowerPoint slides and into the code that eventually enforced that policy. This model however comes with many drawbacks.
The first one is that now, your policy is kept in at least two different locations. With the “main” source of policy still kept in an external document, the implementation in application code risks diverging over time. This might not be a big problem for a few simple policies or a single monolith application, but as the number of policies grow, or big apps get split up into smaller—and often, heterogeneous—components, you’ll soon find that policy scattered everywhere.
Managing changes to policy might now entail updates in many different components, managed by different teams using different technologies. And keeping track of the policy itself isn’t going to be the only problem. For monitoring or auditing purposes, we’ll likely want to keep track of how our policies are enforced over time. Without a consistent way for our applications to log policy decisions, we’re facing the risk of having important policy decisions such as those made for authorization drown in a stream of ordinary application events.
The solution to this is to decouple policy from your application logic, enabling development, updates and management independently of the business logic tied to your application. Most applications already decouple some responsibilities to external systems. This could be things like state, where the application delegates that responsibility to a database, or authentication, where the user is directed to an external identity component. Decoupling policy decisions frees your application from having to deal with roles and permissions, and enables policy lifecycle to be managed independently of your applications and services.
Rego
With policy decoupled from an application, what do the actual policies look like? OPA uses a declarative language called Rego. Rego policies try to mirror real world policies to as large extent as possible. This means that a Rego policy—just like a “real” policy—consists of a set of rules. A rule is then evaluated by OPA in order to make a policy decision. If all the conditions inside of a rule are true, the rule is said to evaluate to true. An example of a simple rule in a HTTP API where we say that “only an administrator should be allowed to create new users” might look like this:

Above we see a simple rule called allow, which will evaluate to true if all the conditions inside of the rule body (inside the curly brackets) evaluate to true. The first condition takes the path of the request from the input (which—as explained in the next section—is one of many possible sources of data), and if it is equal to “/users” continues on to evaluate the next condition. This next condition checks the HTTP method of the request, and if it is a POST request continues on to check the next condition. The last condition of the rule checks the input data for the roles associated with a user, and if one of the roles found while iterating over all provided roles (the [_] construct is for iterating over a list of values) is equal to “admin”, the condition evaluates to true. If all the conditions are true, the allow rule evaluates to true and the request is allowed.
Depending on your previous experience with declarative languages, the syntax of Rego can take some time to get used to, but once the initial unfamiliarity has been overcome, Rego really feels like a natural language for expressing policies and rules.
While built to accommodate the general purpose nature of OPA, Rego is not a general purpose programming language, but a policy language, with features and (150+!) built-in functions tailor made for the context of evaluating policy. Examples of built-in functions include those that help dealing with JSON Web Tokens (JWTs), IP addresses, date and time, strings and regular expressions, JSON and YAML parsing, and much much more. While the next first person shooter game is unlikely to be built with Rego, its versatility as a language has made Rego appear in many places outside of traditional authorization policies (fig. 1-3).

Fig. 1: This REGO example shows that a user “Alice” is allowed to add new dogs to a pet shope API.
Data
In order to make informed policy decisions, we often need to provide our policy with data. To return to a previous example, a policy that says that “any doctor should be allowed to see the medical records of their patients” would need to know both “who is a doctor?” and “who are the doctor’s patients?” in order to make a decision. While it would be possible to include this type of data in the policy itself, the data is often updated more frequently than the policy, and we’d rather keep data of sensitive nature out of our policies, and version control systems like git (remember, policy is code after all!). So, how would we provide that kind of data to OPA? Since data is an integral part of policy decisions, OPA offers several ways.
- Data may be provided as part of the input, i.e. the query that client provides when asking OPA for a decision. This is often the most natural way of providing data that is part of a request. For example, most requests in well architected systems require that the caller authenticates. The result of the authentication is often a number of claims, including things like the user ID, their roles, etc. Providing this information to OPA helps us determine questions like “is the user making the request a doctor?”
- Another option for providing OPA with data is to push data into a running OPA instance. This is a good option when a large dataset is updated frequently and one wants to inject only the data that changed (i.e. the diff) since the last time the data was stored. One drawback of this method is that in order for an external system to reach OPA’s REST API and push updates, OPA needs to be exposed externally. This is alleviated by the pull approach.
- A more common approach is to have OPA periodically pull data (and policy) in the form of bundles (compressed archive files) from a remote endpoint. This has the benefit of not needing to expose the OPA REST API to the outside world, and HTTP caching ensures that bundles are downloaded only when updates have been made. The main drawback of this approach is that currently, there isn’t a way to download only the data that actually changed since the last update. Unless having to work with huge datasets, this has however proven to be less of a problem in real world deployments, where even large bundles are downloaded in just a few seconds. To return to our example of the doctor, this might be a good way to periodically pull down the (naturally, anonymized!) data of patients.
- Both the push and the pull model presents a challenge in that whatever data OPA has been given to work with only is as up to date as when the last push or pull occurred. For situations where this is undesirable, OPA provides a built-in function called:
http.sendWhich allows fetching external data from inside of policies at policy evaluation time. While occasionally necessary, this synchronous way of fetching data introduces an external dependency to a remote system at policy evaluation time, and additionally adds time to the total latency for making a policy decision.
Which method to use depends largely on factors such as the size of the data, and the expected frequency of updates. A combination of the pull model together with providing data as part of the input has proven to be very effective for most OPA deployments. More important than how data is retrieved is what data might be used to enrich the policy decision process. Creative thinking around the use of external data, like using the Google Calendar API for time and event based policies, opens the door not only for new, interesting use cases for policy, but just as much helps in getting more people involved in policy authoring.
Deployment
With an understanding of what policy is, and how to include data from external sources to make informed policy decisions, what steps are needed in order to actually deploy OPA? OPA itself is a small, self-contained executable, and in order to answer policy queries as quickly as possible, ideally runs close to the application for which it makes policy decisions. This means that rather than having a few “centralized” OPAs being queried from many places, each instance of an application runs with its “own” OPA next to it, often on the same host as the application. Since OPA itself is a lightweight process, this doesn’t add a lot of overhead to an application. With applications increasingly split up into smaller components and microservices, it however means that larger organizations might find themselves running hundreds of OPAs in their environment. While the distributed deployment model of OPA is ideal for performance, it poses a few challenges in terms of management.
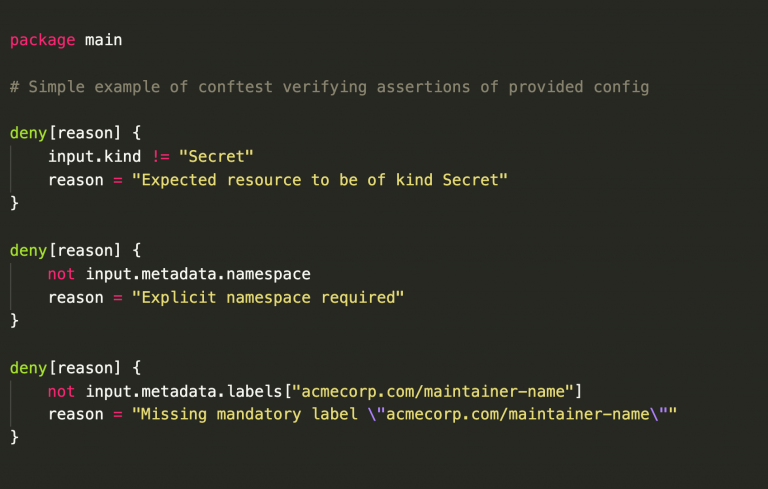
Fig. 2: Pipeline policy where a deployment is allowed only if it is not on weekends and the email address of the deployer ends in “acmecorp.com”.
Management Capabilities
While OPA ideally is deployed as close to the service it is making decisions for, some things are likely best orchestrated from a centralized location. These things include distribution of configuration and policies, collection of health and status updates, and logging of any decisions made.
In order to facilitate this, OPA offers configuration options that allows letting a remote service distribute policy and data bundles, as well as to collect status updates and decision logs from OPAs deployed around an organization. Let’s take a closer look at the most important two – serving policy bundles and logging decisions.
While it’s possible to start OPA with policy files and data loaded from disk, this leaves us with an important question unanswered. What do we do if we need to update the policy or data that OPA needs in order to make decisions? Perhaps a new role has been assigned in an organization, a new resource type has appeared in a cloud account, or we’ve learnt of a new attack vector in our build and deployment scripts and we want our policy to be updated accordingly. If we only have a couple of OPAs running we could probably have the policies updated manually, but what if we have hundreds, or even thousands?
The bundle API allows OPA to instead periodically pull policy and data packages, called bundles, from a remote location. Whenever such a bundle is updated, OPA notices the update, pulls down the latest version of the bundle and loads the new content. This allows policy distribution to be decoupled (see, that word again!) from the actual enforcement of the same policies, and to manage a large fleet of OPAs from a centralized component.
The next management capability worth an extra look is decision logging. OPA is all about making decisions, so it certainly makes sense to later want to know what decisions OPA actually took, and based on what data it had available at the time. This is made possible by the decision logging capabilities of OPA. Just as policies can be loaded from disk for local or small scale deployments, decision logging can be configured to output decisions to the local console. For production deployments however, you’ll likely want to aggregate logs to a central location.
OPAs decision log API allows for that exactly, and will have OPA periodically send compressed packages of decision logs to a server located elsewhere. Just like with bundles, this allows for a centralized management component to collect aggregates of logs, which can later be used to answer questions like “why was user Jane allowed to list salaries?” or “how could the last deployment of network policies be allowed without the appropriate ownership labels being in place?” With auditing being an increasingly common requirement, centralized and safe storage of logs is an absolute necessity.
Styra Declarative Authorization Service (DAS)
With all the management capabilities of OPA available, where do we put the policy bundles, and where do we ship decision logs? And how do we monitor a large fleet of OPAs running inside of our clusters? Setting up your own infrastructure and servers, and writing your own applications for that purpose is… doable, but there’s a much better option available—Styra Declarative Authorization Service (DAS).
From Styra– the creators of the Open Policy Agent – Styra DAS offers a control plane component for managing OPA at scale. Styra DAS provides an advanced, yet easy to use, user interface for managing OPA systems, and to author, test and deploy policies for a wide range of use cases like Kubernetes admission control,Envoy and Istio powered applications, Terraform, API Gateways and service meshes like Kong, application authorization, or any custom system type. Additionally, many of the system types include tailor made policy bundles and customizations, built from the experience of running OPA in large scale production deployments.
The Styra DAS docs do a much better job of listing all the features Styra DAS provides than I ever could, so instead of trying to copy that, here’s my non-comprehensive list of favorite features!
Policy Authoring
With a built-in graphical editor similar to those found in IDEs such as IntelliJ IDEA and VS Code, Styra DAS makes policy authoring a breeze. If you prefer some help along the way, a tool like the policy builder is a great way to get started writing your first policies. For many of the system types, like Kubernetes, Styra DAS additionally ships with ready made policy packages where you can simply pick and choose between common policies that have been thoroughly tested in production environments.
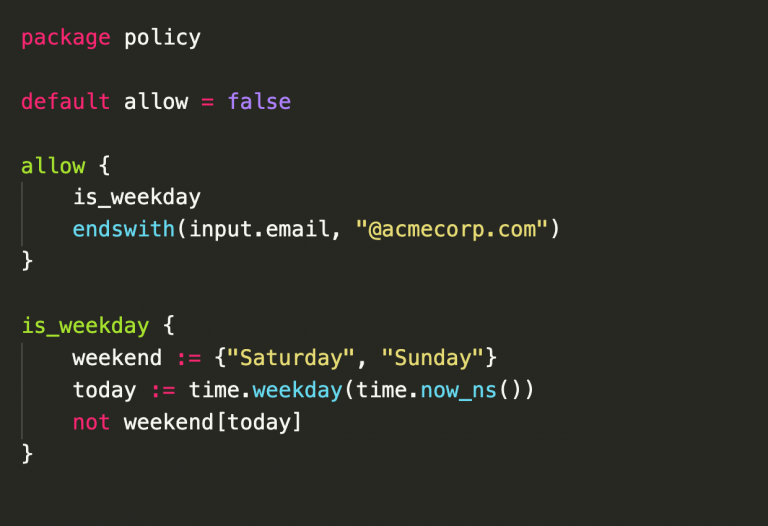
Fig. 3: This policy checks a deployed configuration file – a Kubernetes Secret resource in the example case – for required attributes such as namespace and a maintainer label.
Git Integration
Authoring policies is just the first step of the policy life cycle. While you can have Styra DAS store your policies for you, production configurations ideally use git to manage policy code as any other code—including automation of tests, code reviews and pre-deployment checks. In order to do that, Styra DAS integrates seamlessly with repositories like GitHub, and allows you to save policy updates to feature branches that may be reviewed and tested prior to deployment.
Decision Logging
As we’ve previously learnt, decision logging helps us answer what policy decisions have been made in the past. This knowledge is important not just in terms of auditing past decisions, but also to help us improve future policy. Decisions of special interest commonly include denied access to systems, but probably even more frightening is of course the thought of someone having obtained access to systems they should not have been allowed to access! While sending logs to a remote system is the first step, it isn’t particularly useful unless that remote system actually handles the logs in a meaningful way.
Styra DAS makes decision logging an integral part of managing OPA at scale, providing visibility in the form of dashboards showing an overview of decisions made, per system or for the whole control plane. This enables an administrator to quickly spot deviations from what is expected, like unusually high frequencies of denied decisions or errors encountered in policy queries. Once identified, the decision log view allows an admin to filter out log entries of interest, or even use free text search to find things that could be worth looking into.
Impact Analysis
My favorite example of how decision logging is useful not only to know what happened in the past— but just as much to improve future policy decisions—is the “impact analysis” feature. This combines the policy authoring capabilities of Styra DAS with decision logging, allowing a policy author or admin to replay changes in a policy over the history of past decisions. This effectively provides a policy author a “what if” button to answer how a change to a policy (like adding a new rule) would affect decisions taken in the past. This, together with the unit testing capabilities of OPA and Styra DAS, provides a great level of assurance that changes can be rolled out without breaking existing use cases.
Testing
Unit testing is an important step in the policy life cycle. Not only does it help us test for cases we expect (or don’t expect), but an extensive test suite helps us build confidence in our policies and data over time. Would a change in policy A have consequences for policy B? With tests in place we’d know immediately. OPA comes with a tool for unit testing policies, and Styra DAS takes it to the next level by visualizing code coverage, or combining tests with impact analysis in order to really know that changes won’t break production use cases.
Libraries
Finally, another favorite feature of mine in Styra DAS is libraries. As large organizations tend to have hundreds of systems, there’s bound to be policy rules and helper functions that many of them have in common. Libraries help with just that by providing policy code (sourced from git, naturally!) that is shared between OPAs deployed in an organization.
Wrapping Up
As more and more organizations realize the value of treating policy as code, decoupled from business logic and application concerns, the general purpose nature of OPA presents a common solution for applying policy to use cases as disparate as infrastructure, build and deployment pipelines, data filtering, application authorization and much more. With a common language to describe policy, and common procedures for authoring, testing and deploying policy, OPA is the natural choice for bringing the policy as code concept into organizations of all sizes.
Coupled with Styra DAS, organizations gain management capabilities for large scale deployments, and a user interface for managing everything around the policy lifecycle.
Regardless of which stage you are currently at in your journey towards policy as code, I hope you will consider OPA and Styra DAS as tools to help you get there!

Anders Eknert
Developer Advocate at Styra with a long background in identity systems. When he’s not working with OPA, he enjoys cooking, food, football and Belgian beers.
Twitter: https://twitter.com/anderseknert
LinkedIn: https://www.linkedin.com/in/anderseknert/
GitHub: https://github.com/anderseknert/