Interview with data journalist Sebastian Vollnhals
The first time I encountered a password was when my four years older sister tried to prevent me from entering her secret play bunk. Upsettingly enough she didn’t give the password to me and I was locked out. As an adult however, I use passwords every day for many purposes: logging into accounts, retrieving my emails, accessing applications, databases, networks, websites, and also my subscriptions. Moreover, this is the case for every typical computer user.
If one password tells us how to verify the user, what does a collection of several passwords tells us? And what happens when the passwords are no longer a secret? To find out more I talked to a data journalist. Sebastian Vollnhals worked half a year on the project Heatscore with the Infographic Group in Berlin, and I asked him if he could explain it to us further:

What can this information be used for?
The point in data journalism is of course to give people insight to the information and to trans form that information into something that people can understand and benefit from. But in a broader sense; for the information security realm it would contribute to a deeper understanding how passwords are constructed. The more we understand how people behave, what’s on their minds and what the patterns are, the more we can check if these patterns apply in specific passwords and from there make an assumption of how good a password really is. This is helpful information to contribute to improve data security. Even when you type a password that fulfills the policies that are in place, it still adheres to a lot of the patterns. It is no longer a good pass word when patterns show that it is more predict able than a random password and thereby more vulnerable.
Tell us about the project
The project in itself came to be in the view of the so far largest leak, the largest collection of com promised user accounts that surfaced in the be ginning of 2019. The socalled collection or collection No.1 in the beginning. Later on, there was also a second release, called collection No.25. All in all, it was a big collection of compromised data.
It all originated from what is in the media called the Dark Web, places where illicit actors on the internet meet for exchange and trade. These places are like underground forums where people can sell for example stolen credit card data, hacking tools, fraud tools or services for criminal activity. And also compromised user accounts. It is pretty common for these actors to simply hack into websites, compromise the database, dump all the data and from there sell it of for a profit.
There are even sites where buyers can closeout the information exclusively, meaning only they have the data. And it is possible to buy data that is not exclusive, everyone can buy it, and there fore not guaranteed if you can defraud someone when everyone knows the data as already tried.
The base for the data and the collection is really, really vast. Over 500 gigabytes of compressed data. And when you think about it, it is not like videos or images, basically more text data. It is like username passwords addresses, some metadata in lot of cases.
When I later dug into it, it consisted of around ten billion accounts, but not necessarily unique accounts. The data is very messy with a lot of it as duplicates or broken data. But roughly ten billion accounts in the data, ten billion records of some sort of compromised credentials in one form or another.
In the beginning of 2019 was the first time this data went beyond its trading circles of criminal actors and became public. The data was bought or derived and then got published. This made it accessible basically to everyone technically speaking and it was now possible to obtain the data without having to pay for it. And that was exactly what a lot of people in the information security community did. One example for that is Troy Hunt. He is providing a big database where it is possible to put in an email address and he will then tell you where it shows up. As in, on which leaks and where your email address has been used. This allows you to be aware of where and if your account for the websites that you use have been compromised and where your data might have been lost. The site is called “Have I Been Pwned?” It is a very useful service and I as a data journalist was interested in the data inasmuch as I wanted to analyze what passwords are made of and what are the habits of people when they think of passwords?
A lot of the times a lot of the data is not in cleartext password. That is not that uncommon, while usually what happens is that when the pass words get saved by a website or a server they are not saved in clear text. Usually they are saved as hash or fingerprint that are generated from them. There are some methods that counter easy reversing this. Which means that when the website is hacked, the hackers cannot read the cleartext passwords.
But in order to obtain the passwords, there are some methods to use still. Like brute forcing, trying out all the possible passwords and see if there is a match. When a site has been compromised, it is possible just wait for you to log in and snatch the password when you send it while log in to that website. This then provides a good improvement on trying every password and trying only the passwords that are likely people use.
To figure out likely passwords means learning about people’s habits when creating pass word. And also learning about the policies that the password has to conform with, to lower the search space. A lot of times people just put in this vast number of encrypted passwords and try a lot of different ones and they can get really good rates on guessing the passwords. There are even people specializing in this field. For example, when a website has been hacked there is a dump, but the passwords are hash. Still we were able to guess 90% of them because people are not very creative or not very unique when it comes to thinking of passwords.
And this was really something that I wanted to investigate. This very large dataset is a good sample. Not for everyone though. This is not good for scientific research. Because you don’t know the sources, you don’t know the methods in which data has been obtained , you don’t know what processing has been done, you basically know very little of the data and a lot of it is also problematic then data has been compromised when processing it. Some datasets are the same but, in the data, they are described to be from different sources and a lot of it doesn’t make a lot of sense. Therefore, it does not qualify as a good basic for scientific research, but it is a good way to learn about the big picture, general trends and about how people behave. Augmented it was very interesting.
It was a lot of work to clean up the data and get into machinereadable state. On the grounds that the people who were compiling the data were using different methods, the data is from different sources, from different data breaches, they have been extruded or they have been obtained in different ways and different data format. Everyone cooks their own soup. This made it a tougher job to go from five hundred gigabyte of miscellanies files in different formats to some thing that can actually be analyzed with computer software. I had to figure out which data formats were used, and I had to figure out which errors were made. Basically, I had to try to think of all the caveats that can happen when processing that much data. This takes a lot of computational time with ten billion records, which also created the need to streamline my own process so that it would be possible to get to a result within a reasonable amount of time. Exceeding, it is import ant to keep in mind that when you make some wrong assumptions along the way, you might be forced to go back do all of your steps again to weed out some errors that wouldn’t have been fixable later. This took quite a lot of time. It was basically three months of working with the data in order to get as much out of it as was possible and filtering a lot of the data out.
“To figure out likely passwords means learning about people’s habits when creating password.”
As things go, what I tried to add up in the end was a list of cleartext password and how many times they had occurred in the data. Suitably, I think I got pretty close to that. I had to weed out a lot of things. Like I mentioned earlier data is saved as hashes, as cryptographic fingerprints of passwords. Seeing to that, it is not straight forward, not obvious what the actual password is. In a lot of cases it would just put the hashes in the data with no distinction, this is not a password; it is a hash. Therefore, I had to figure out a lot of what format the hashes were in, in order to sort them out. Usually this is doable in many cases, since hashes tend to be really long numbers that stick to certain formats, but some of the ways the passwords are hashed make them distinguish for a good password.
I would say there are also some bad ways to hash a password that look like it could actually be a good password, so therefore I also had to look within the file if it’s all in the same format.
If it all looks the same, then it is likely to only be hashes. Considering, if the passwords consist of certain characters, like everything is ten characters long, that is not happening in real life, you wouldn’t have a website where every password is ten characters long except if you enforce that but that wouldn’t make sense.
Moving forward I had to weed out a lot of stuff that weren’t actually cleartext passwords, a lot of passwords that were broken. Supplementary, at some point the data was used in Microsoft excel and many of us know, excel really likes to convert into its own formats.
Comparable, trying to type a post code some where in Saxony, and it starts with a zero. Excel will think this is a number, throw away the zero in the beginning and you end up with a fournumber post code instead. That is something that happens to passwords too. So, when someone is using a very long sequence of number as their password, Excel will say: “yäy, let’s convert it to an exponential format that looks nicer!” Inherently, that is of course not a cleartext password anymore and there are in some cases no way to recover what the cleartext was, thus we had to filter that out as well. Consequently, a lot of data wrangling was done in the end.
After ending up with lists of passwords and numbers with their occurrence, I basically had my first result right there. Now I knew what in the dataset is the most common password and this is a really interesting find. Once visible it became obvious – the most popular passwords are “12345678”, “password”, “123456” and “qwerty” and all that good stuff. This was an expected result that also made sense.
Then I could gander more into the material and find other ways to analyze it and also look deeper into the data and observe the still popular, but not top ten popular, passwords to find oddities and occurrences that were harder to explain on the first glance.
For example, in the five hundred most common passwords there are plenty of them that look good, look though. They are long, they have random characters and they are not made of words. This wouldn’t make sense because it is unlikely that a lot of people think of the same totally random password. Why is that? And this became a starting point to look more into the data and see where these passwords are used. What are the sorts of accounts they are associated with? One could figure out that this is a password that is used a lot because it is used by spammers. Consequently, they write programs that create a lot of accounts on websites like social media sites or email providers along with others, and then just make one password once that is good. But they don’t change it before register thou sands or hundred thousand of accounts on the websites. Always with the same passwords and this is why some really good passwords ended up looking very popular.
This is one of the stories behind the data. Yes, spammers create millions of accounts and use the same passwords on many of them. Not only the same thou, there are a few passwords and different spammers will use different passwords and there are also very popular shitty passwords that are used by spammers a lot. For example, when Myspace was hacked the most popular password was homeless pa. This is a simple password, but it is not something that hundred thousand people would come up with. It is not as obvious as 123456 for example but is however distinct enough and it was from all the fake Myspace accounts some people were creating to spam. From there it turned out to be the most popular password on Myspace. Not the most popular human password, but the most popular password in that dataset and it even showed up in the bigger dataset the collection of breaches.
So much information! But what can you do with it?
There are many outcomes. The thing, or one of the things I do is try to think of questions that I want to answer with the data that are not so obvious at the first glance. I want to answer questions like “how many good passwords are in there?” “Are there certain trends?” “Are there certain not so obvious behaviors people would do and discoveries that could be found or just I really want to know what sort of characters people use in passwords?”
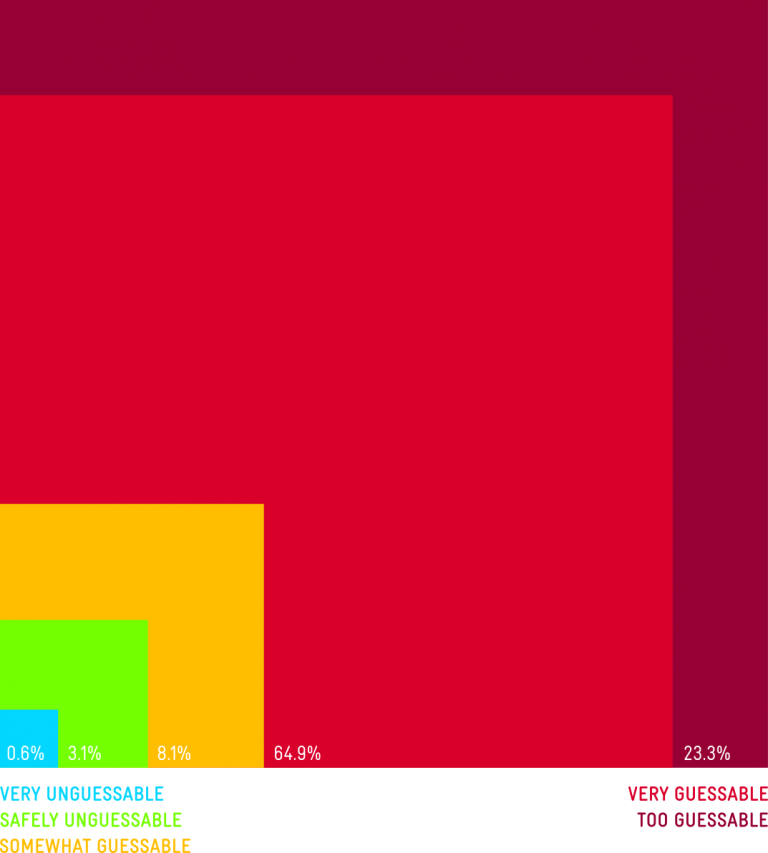
When you sign up on a website your password must fulfill some specific requirements. It has to be a certain length, it has to contain upper case characters, a number and a special character but only certain special characters are allowed and so on. I really wanted to know about the distribution of special characters in passwords for example. In such manner I classified all the characters in passwords and specified az character or uppercase az upper case characters, numbers and everything else. Then I basically made a plot for passwords. I sorted the passwords by lengths and then into length categories from 3 to 30 something characters. I made dots and I accumulated if in the position of every password for every position there was a special character. For example; I would add two dots in this position so in the end the dots contained more of the characters I was looking for, would be more visible and the other ones would be more transparent. This allowed me to so see the distribution of for special characters in passwords with a certain length and sorted all the dots in a pyramid shape under each other like three characters on top 30 characters in the bottom row.
“Turns out those keyboard pattern passwords are actually quite popular and a really easy guess for someone who wants to crack your password.”
This would paint a good visual representation of where the special characters in the passwords are and there were some trends to be found. In the shorter passwords, lower numbers like ten or twelve characters, there was a tendency for people to put special characters in the end. Something that often happens if you are forced to choose a special character with your password. People would just add a dot or an exclamation mark or a dollar sign in the end. And there was also a slight trend to put one in front. This is a behavior pattern that make sense. When you look at it, this would even show up in the data so there was a trend, there was a behavioral pattern. This helps when trying to predict how people would construct passwords, which is a very broad field in security.
This creates a dilemma. Indeed, you want of course your accounts to have passwords that are not so predictable, but it is really hard to come up with rule sets to make behaviors go away.
On the other hand, with the special characters in the longer passwords, and I have to say short passwords are more common. The bulk of data shows that eight, nine characters make up 90 % of the passwords and longer passwords are very uncommon. So, for longer passwords, the data wasn’t as dense anymore, but enough for a trend to show up. Especially the longer the passwords got. There would be a special character in the fourth to last place in the tenth, eleventh, twelfth to last place. That wasn’t so clear, but it was a line going through the pyramid and you could really see there was some sort of pattern. It looked interesting and on first glance, why would people put a special character in these strange places and so consistent? And then I followed up by taking a sample of longer passwords and discovered that people were using email addresses as passwords and the special character is the dot in .com. Next, you could see one line for when the domain was five characters long which is Gmail or yahoo and there was on seven characters long which is Hotmail and you could basically see in the visual representation of the data the email services people are using just from this analyzes. This was really intriguing, it was something that I did not expect to find but thinking about it, it makes sense. The email address is something that people can remember, it is something they probably type in anyway when they have to type their login and it is something that quite fill all the requirements of having a special character in the password and having a certain length. For a lot of people this is a shortcut to remember their passwords. It is not a recommended one, but it is a behavior that happens.

Keyboard with Stickers for Russian Letters
Did you feel like you got the answer to all the questions that you wanted?
I don’t even think that I got all the questions! The data is so vast and there is so much information there. I think I didn’t even come up with the bulk of the questions that could be asked. It is interesting and one could probably spend years analyzing the data and find new things. Of course, as a data journalist who works with the assumption that I have to produce stories within a reasonable timeframe, I enforce findings that are straight for ward obtainable but also gives some new insight, broadens or base of knowledge, that makes us learn something new. Similarly, there are obvious stuff like “what is the most popular password?” That is something to get peoples interest with, but there is also an interest in results like; What are the stories behind the passwords? One ex ample of that is the complicated password that turned out to be spammers. Why are people choosing like they do? What are the patterns and behaviors? One really common pattern is people are not that different. As when we think that we are very brilliant by not typing the name of our dog as a password but instead try to remember patterns on the keyboards and press buttons in a certain way to produce something that look really random. Truth is, this is still is very repeatable and still a behavior that can be expected. Expanded, when we think; “Hahaha, I’m NOT writing qwerty. I’m writing zxcvbn, because I’m using the lower row, no one could guess that!” But again, a lot of people can guess that. Turns out those keyboard pattern passwords are actually quite popular and a really easy guess for someone who wants to crack your password. Thereupon; those are some of the learnings from this project. I try to find a level where I’m not too trivial, but I do cover some of the trivial stuff as well as it was what people expect to learn. I also try to cover the information that is out of the knowledge yet but it’s still grasp able to the reader.

And if our readers now all want to change their passwords after reading this, what would you recommend?
They should! I recommend two things basically; You need your password to be random, you need your password to be unpredictable, out of the ordinary. And this is a task human can’t do, humans will always apply human behavior. Even if you smash your head on the keyboard it will produce something that isn’t so random. What you really need to do is not think of passwords but instead use a software that creates good, long, random passwords. A software that makes use of all the characters available and that makes the password as long as the website will accept it. This is a functionality that is built into password managers.
The second thing is never to reuse the same password. We want to try to remember some thing and we finally have remembered our very complicated, what we think is very unique, pass word and we want to use it everywhere. But this is really the deepest trouble you can get in. Whereas, when you reuse your password on different sites, if it is compromised on one site it is compromised everywhere. This is also a problem that a password manager can help you with. There are a lot of them out there, I don’t recommend a specific product or service. But do your research, see what password manager fits for you and have a look if the password manager has had security issues in the past and choose the one that didn’t. Choose the ones that are used by many people. And probably a good point is to go towards the ones who are open source and where your passwords are stored not only in the cloud, but also where you have access to them.
If you have stored passwords in your browser; be mindful that is something you shouldn’t really do. Owing to that in it is not really safe unless you encrypt it also in the browser, but just “remember my password” is not a safe thing to do. If you already use a password service, go over your ac counts and update the passwords to new ones. You don’t need to change them every time in regular interwall, that is not really necessary. You should do that when there is a breach on a specific service. One of the advantages is that you have one password per service, if it gets compromised it will only be at this service and you can change it. You don’t have to go to every website to log in and find out what the password changes procedures are in case of a data breach.
The password for the password manager is the password you have to remember. Choose a good one. Create a reasonably long random password and with reasonably long I mean twelve characters at least. That may sound like a lot, but it is doable. One password – twelve characters. Give it some practice and you can remember it. Or use some of the tactic’s for long passwords. Xkcd have a famous comic for this; make a password that consists of four words. It creates a lot of search space and it is easier on our minds to remember. In the end, we are not software, we are not computers. We are humans and we work better with things that plays a role in our life like words of things and we can visualize these things in our minds. This is how we can remember pass words. This is something you can do if you want to still use a human pattern but a pattern that is safer than 123456 or your doggies name or your birthday.
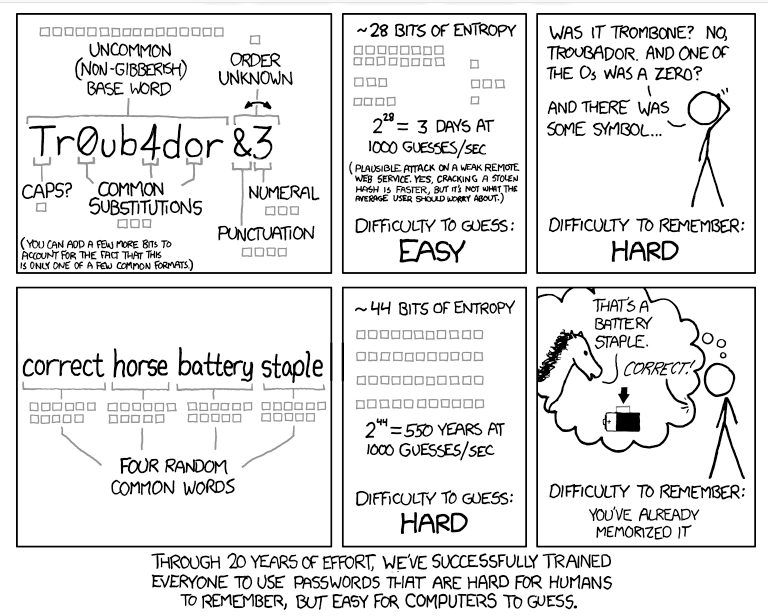
(Source: https://xkcd.com/936/)
Fun fact: in the comic he uses the example of “correct battery horse staple” This a staple and a battery and the horse says it is correct, so you can remember it. And doubtlessly; “correct battery horse staple” would show up in the leaked passwords data. So, it is fair to say that a lot of many people read the advice but not everyone really got it.
Thank you so much for participating!
After the interview was conducted the Heatscore project got published. You can find it here https://info.graphics/stories/heatscorepasswordpatterns
The interview was conducted by Emelie Gustafsson.