What is Function Mesh
Function Mesh is a Kubernetes operator that enables users to run [Pulsar Functions][1] and [connectors][2] natively on Kubernetes, unlocking the full power of Kubernetes’ features and resources. For example, Function Mesh uses Kubernetes’ scheduling functionality, which ensures that functions are resilient to failures and can be scheduled properly at any time. Function Mesh is particularly interesting to users who are looking to create complex streaming jobs with multiple Pulsar Function. By providing a serverless framework that enables users to organize a collection of Pulsar Functions and connectors, it simplifies the process of creating complex streaming jobs. Function Mesh is a valuable tool for those who are seeking cloud-native serverless streaming solutions. Key benefits include:
- Makes Pulsar Functions and connectors easier to manage when multiple functions and connectors are being used
- Enables users of Pulsar Functions and connectors to utilize the full power of Kubernetes Scheduler, including rebalancing, rescheduling, fault-tolerance, and
- Makes Pulsar Functions and connectors a first-class citizen in the cloud environment, which leads to greater possibilities when more resources become available in the cloud.
- Enables Pulsar Functions to work with different messaging systems and to integrate with existing tools in the cloud environment (Function Mesh runs Pulsar Functions and connectors separately from Pulsar).
Function Mesh is well-suited for common, lightweight streaming use cases, such as ETL jobs, and is not intended to be used as a full-power streaming engine.
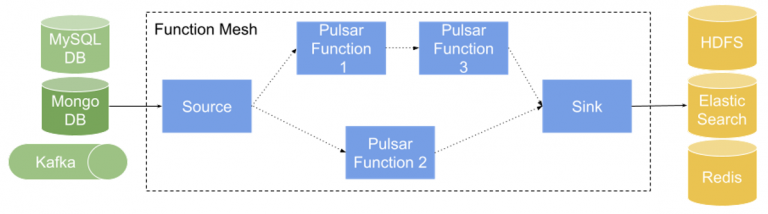
Why Function Mesh
Pulsar Functions are Lambda-style functions designed for serverless event-streaming with Apache Pulsar and support different deployment modes. For example, you can run Pulsar Functions with the broker, manage it by a dedicated Function worker, or run it on Kubernetes after configuration. However, Pulsar Functions are not Kubernetes-native, so they do not leverage all the tools provided by the Kubernetes ecosystem. This made it hard for users deploying Pulsar Functions in Kubernetes to implement certain features, such as auto-scaling, and led to some issues, such as broker crash loops and inconsistent function metadata management. With the rapid adoption of Kubernetes over the past several years, it has quickly become the standard for automating deployment, scaling, and management of containerized applications. To streamline the adoption and ease of use of Pulsar Functions, it made sense to seek a solution built for Kubernetes.
Additionally, with the increased demand for a serverless framework able to compose multiple functions into a single streaming job, we saw a big opportunity to improve how users run several correlated functions at a time. Without Function Mesh, there is a lot of manual work to process data input and to organize the different Pulsar Functions, making it hard to manage a bundle of functions. Also, functions are tied to a specific Pulsar cluster, making it difficult to use functions across multiple Pulsar clusters.
To solve the pain points and make Pulsar Functions Kubernetes-native, we developed Function Mesh — a cloud native and integral way to run Pulsar Functions. You can use Function Mesh as a Kubernetes operator and run single Functions and connectors on Kubernetes, and you can also use it as a framework and manage multiple functions and connectors together.
How Function Mesh works
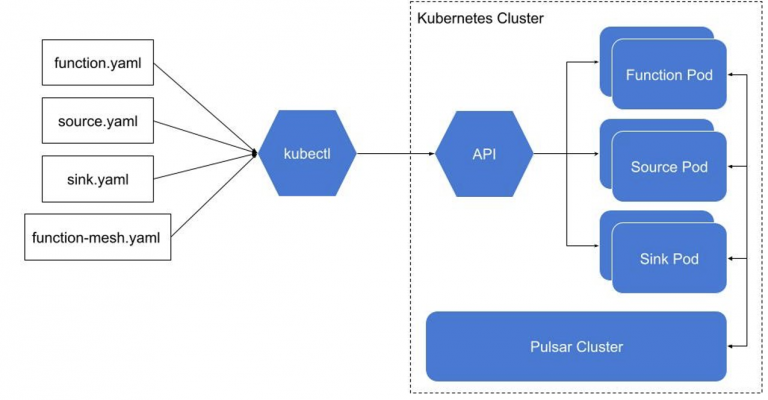
Function Mesh is designed to run Pulsar Functions and connectors natively on Kubernetes. Instead of using the Pulsar admin CLI tool and sending function requests to Pulsar clusters, you can use kubectl to submit a Function Mesh CRD (CustomResourceDefinitions) manifest directly to Kubernetes clusters. The corresponding Mesh operator installed inside Kubernetes will launch functions individually, organize scheduling, and load balance them together.
Function Mesh works in this way, and both the metadata and running state are stored directly in Kubernetes.
- Create Pulsar Functions, source, sink, and Function Mesh `.yaml` files as
- The Functions controller receives CRDs from Kubernetes service and then schedules the individual pod for running function/connector
- The running function/connector instances run with the configured Pulsar cluster and
The following diagram illustrates the process of Function Mesh.
(/static/images/blogs/fmbeta/3.png)
Try Function Mesh
Function Mesh is now open source https://github.com/streamnative/function-mesh, try it on your Kubernetes clusters.
To learn more about Function Mesh https://functionmesh.io/docs/ and https://www.youtube.com/watch?v=VGtFz0mWKfY.
If you have any feedback or suggestions for this project, feel free to mail to: function-mesh@streamnative.io or open issues in the github repo. Any feedback is highly appreciated.
[1] http://pulsar.apache.org/docs/en/next/functions-overview/
[2] http://pulsar.apache.org/docs/en/next/io-overview/
For further informations reach out to Carolyn King at Carolyn@streamnative.io